Until not so long ago, the most normal way of approaching the construction of a software solution was in a monolithic way, all the necessary elements were compiled within the same application. This way of working is very fast due to its simplicity of design, but it means that the dependencies between the different parts of the solution are tightly coupled, so that when a part of the application is touched, all of it can be affected and how much the larger the application and the more functionalities added, the more difficult it is to maintain it with optimal performance and free of problems, which implies that the release cycle is longer.
Through the use of patterns such as MVC (Model — View — Controller) it is possible to decouple in a certain way the data, the interface and the control logic, being able to carry them out separately; this decoupling between the layers offers the freedom to be able to modify, for example, the interface without the need to change business logic code, which substantially reduces the tests to be carried out on each change and thus the software release cycles.
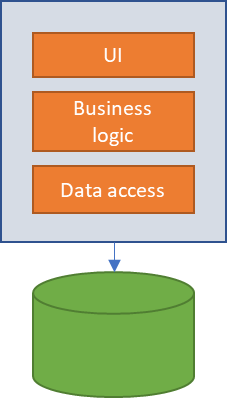
But this is not enough, when new applications are generated within a company, certain functionalities are repeated among them, for example, consulting information from a client, obtaining stock of a material… the examples are innumerable. Suppose we need to obtain the information of a client in three different applications, in a monolithic design, each application would have its own access code to the client, and it could even be that it had its own database, thus losing the consistency of the data in the company and duplicating functionalities. If access to customer information had to be modified (for example, due to a database change), we would have to redo the three applications and test them again, with the consequent cost in time and resources; that is, money.
Thanks to service-oriented architecture (SOA), many of these problems were solved. By breaking the application into different services and making them available through an enterprise service bus (ESB), applications that need to query information from a customer would only have to connect to the ESB and use the corresponding service, just one for all the applications. This architecture has an Achilles heel: the ESB. In the event that the ESB does not work, all applications that depend on it will be rendered useless.
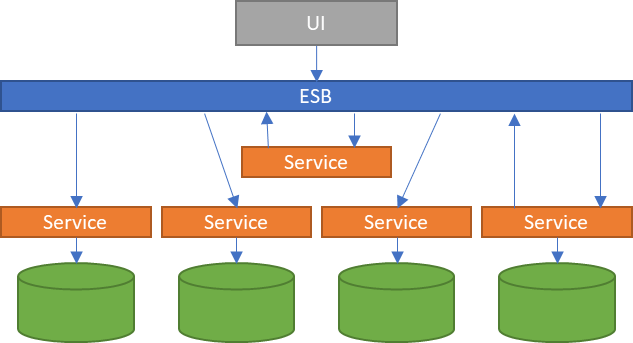
The microservice architecture goes one step further, an evolution of SOA allowing direct communication between services, thus eliminating the problem of dependency on an ESB that orchestrates calls between them.
This architecture will allow us to develop applications as a set of small services that run in isolation, in their own process (even machine) and that communicate with each other (there is no ESB) through lightweight protocols, container technology has helped to all of this, being able to break applications into small self-sufficient and self-contained services, being able to include their own databases, we will talk deeper about them in another article.
Surely the reader is already seeing that this architecture has many advantages, but it also has drawbacks that we will see later.
One thing that must be taken into account is that when working with microservices, not only changes the way of thinking about the architecture of the solution at the code level, but there is also a restructuring of the teams to develop these parts of the application, working in a separate way, but must be prepared to communicate with each other (teams and services) and be able to respond to failures when calling other services.
One of the great advantages that we have when working with separate teams to develop each of these microservices is that they can use different technologies for each microservices and simply by publishing the API (Application Programming Interface) to work together with other teams and services through a protocol agreed and without hard coupling between functions.
Dividing the application into microservices, we can create separate work groups, facilitating the implementation of agile methodologies for development, where we can have, for example, a squad totally focused on treasury reporting that develops the microservice in Java and another squad focused on creating a microservice of collection forecast developed in R language. The fact of working in different technologies (and not knowing them in advance) does not prevent the services from calling each other and also allows each of the teams to work at their own pace, they just have to make sure that their part works, and share in this way a functionality between several processes and applications while maintaining a loosely coupling.
Microservices are self-contained functionalities, that is, they can work separately by carrying out that action for which they were designed, being able to make individual deployments of each one of them, favoring, among many other things, the CI/CD processes. Just as they work separately, they also fail separately, which is great news too, because if a microservice goes down, only that part of the application stops working, but the rest of the application can continue working without a problem.
Despite their advantages for the scalability and resilience of the solution, microservices also have disadvantages that must be taken into account during development, such as the complexity of integration tests, greater security challenges, increasing network traffic due to remote calls, etc.
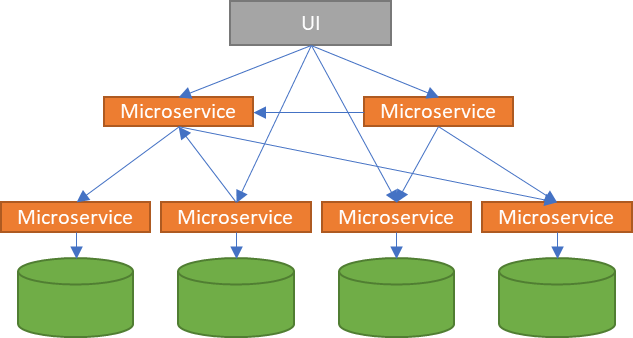
When a microservice architecture grows, given that the different microservices can be called freely, we will find ourselves in a situation in which the services will be tied together so that it will be very difficult to know which microservice is called by what microservice and the implications that it can have in other processes when we make a change in one of the microservices.
At this point, we have moved from a monolithic application where each change involved compiling, testing and deploying the entire application to a bunch of microservices, capable of communicating with each other to facilitate scalability and resilience, but as the microservices landscape grows, so does the difficulty to understand the workflow and more complex is to maintain the solution.
To facilitate the management of the microservices landscape, we can rely on event-driven architectures (EDA), since they adapt very well to microservices and will allow us to overcome some of the drawbacks that we have seen previously.
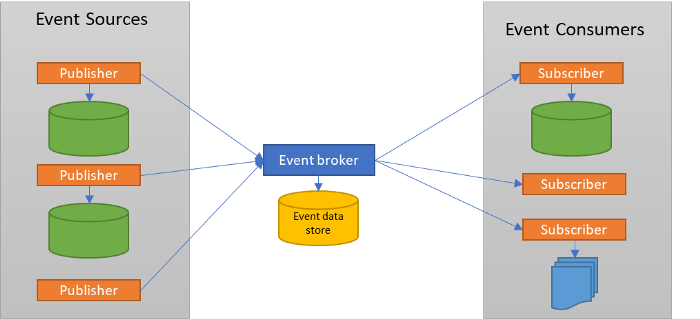
In an event-driven architecture, when a system makes a change in its domain, it informs the outside world through an event. The issuer is simply responsible for announcing that change, but it does not matter if there is another system listening or what it does with the notice it has issued, for example, when we are buying on a website and click on “add to cart”, the system it would announce that “the object has been added to the cart”, that other systems can listen (or not) and act on that event, for example the event can serve to know that another system has to block stock, or that it has to show others items related to the item just added to the cart, etc. In this way, it is very easy to add new services to the ecosystem, they simply have to air events of the actions that have occurred and the rest of the services will be in charge of listening and acting in relation to this call or listening the events launched by others, acting as a consumer and reacting on them.
From the business point of view, when a process to be covered by the application is expressed, it refers to actions that are linked and with dependencies between them; to see how the process has been covered by events that are aired by microservices and the order in which they are executed is much simpler than a black box of a monolithic application; it is much easier to see that after event A the event B should be executed, than not to press a button and obtain a result that is not known how it was obtained because it is obfuscated in the internal logic of the application.
When it comes to emitting events, it can be done using different patterns, some of them are:
- Event Notification.In this pattern, we simply indicate what has happened, without giving much more information, it is the simplest pattern to implement at the event level, but it has other drawbacks, for example, we could issue an event of “The purchase has been made”, and the consumers of the event, have to be in charge of asking what they have bought, or if a discount has been applied, or other tasks that the services that have listened to the event can perform, and this can generate a cascade of calls by each consumer to obtain the data they need.
- Event-Carried State Transfer. In this pattern, in addition to sending the event, a status of the issuing system is sent, in the previous example, in addition to notifying that the purchase has been made, the message could carry data about the items purchased, discounts applied, billing address , etc. This information can be used by consumers of the event, without having to have additional calls.
- Event Sourcing.The idea of this pattern is that any change that is made in a system is registered as an event and is recorded in a log, so that we can reconstruct the state of the system from the history of events produced in it, becoming the event store at the single point of truth.
There are multiple solution for managing messages and sending them between systems and microservices such as Rabbit MQ, AWS Kinesis and others, although the most used solution is probably Apache Kafka.
Without going into much detail in this article (we will do it in another), Kafka allow us to manage event queues, create partitions to balance loads between different senders and receivers, keep a record of all the events and their states, use connectors for different systems, etc., and all this handling large volumes of information flows in a distributed manner, and what does this mean at the level of scalability and resilience? It means a lot.
We have already seen that through Kafka, introducing new event generators, processors or consumers is something simple (register, emit and consume events) and we could do it with zero downtime, balancing the load between those available, but also, Kafka can maintain a database with all the history of the events that occurred in the systems and the data associated with them, so that in the event that a node with its corresponding microservices and databases stopped working, we could build a new node and feed on the necessary events stored in Kafka, reaching the data state of the previous node in a very short time and automatically. Interesting, right?
As a conclusion we can say that with the arrival of cloud services, there is an increasing need to develop microservices so that we have very flexible and loosely coupled applications, but to achieve a good result in the application, it is necessary to work these microservices in a way that be maintainable and traceable as well as safe and resilient. Event-driven architecture (EDA) has many features that make it a very good option for using microservices. Although there are many platforms for event management, Apache Kafka is one of the most used, with great scalability and performance, offering among others, subscription queuing services, data transformation, replication, or distributed logs.
1 thought on “From monolithic to event-driven architectures, a brief review of the journey”