Quizá por la imagen de la entrada, alguien se piense que hablaremos de agentes especiales como 007, pero no, hablaremos de otro tipo de agentes. Quien más o quien menos, utiliza la IA generativa en su día a día. Quizá uno de los mayores problemas que hemos podido encontrarnos al usarla es que, en ocasiones, damos con modelos o chats que no pueden ofrecernos información actualizada, es decir, no podemos preguntar por cosas que han pasado en el pasado cercano, como por ejemplo quién gano la carrera de F1 del último fin de semana. Por ejemplo, el modelo Generative Pre-trained Transformer 3.5 (GPT-3.5) se hizo público el 15 de Marzo de 2022 y fue entrenado con datos disponibles en ciertas fuentes hasta Junio del 2021. Esto significa que el chat podía contestar correctamente a nada que hubiera sucedido después de Junio del 2021.
La realidad es que para entrenar un modelo, se tarda bastante tiempo y se necesita una gran cantidad de recursos informáticos, por lo que no es posible estar entrenando el modelo cada minuto para ofrecer información completamente actualizada.
Para superar este problema y ampliar las capacidades de los modelos de lenguaje tradicionales es por lo que surgen los agentes.
A diferencia de los modelos independientes limitados por sus datos de entrenamiento, los agentes combinan razonamiento, herramientas externas y acceso a datos en tiempo real para abordar tareas complejas de forma autónoma. Los modelos de lenguaje extenso (LLM) son estáticos, están limitados a sus datos de entrenamiento y suelen proporcionar respuestas de una sola vuelta (teniendo en cuenta el contexto). Los agentes, sin embargo, gestionan el historial de sesiones, utilizan herramientas de forma nativa y emplean marcos de razonamiento para manejar interacciones complejas que pueden incorporar varios pasos. Por ejemplo, un modelo podría responder «¿Qué tiempo hace hoy?», basándose en su entrenamiento, y seguramente alucinando por información obsoleta. Si contamos con agente equipado con una herramienta API meteorológica, podríamos obtener datos en tiempo real y ofrecer una respuesta precisa y actualizada. Esta capacidad de ampliar el conocimiento y actuar de forma dinámica hace que los agentes sean piedra angular para las aplicaciones prácticas.
En esencia, los agentes de IA generativa son aplicaciones diseñadas para, de manera autónoma, lograr objetivos específicos mediante la observación de su entorno (y la actuación sobre el entorno) utilizando un conjunto de herramientas.
Estos agentes van más allá del simple procesamiento del lenguaje natural (que generan respuestas basadas únicamente en conocimientos preconcebidos), abarcando capacidades como la toma de decisiones, la resolución de problemas y la interacción con entornos externos. Podemos pensar en ellos como asistentes digitales que no solo entienden la solicitud, sino que también pueden obtener información en tiempo real, interactuar con APIs o incluso ejecutar tareas como enviar correos electrónicos o controlar sistemas, todo ello sin supervisión humana constante.
Podemos describir los agentes con la siguiente arquitectura.
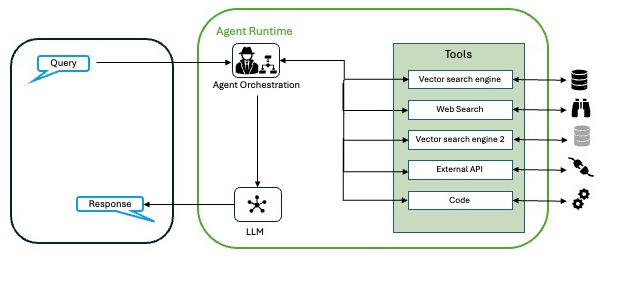
- El modelo: es el modelo de lenguaje (LLM) que actúa como cerebro para la toma de decisiones. Puede ser un modelo único o una combinación de modelos (pequeños o grandes, de propósito general o afinados) capaces de seguir marcos de razonamiento como Reason and Act (ReAct), Chain-of-Thought (CoT) o Tree-of-Thoughts (ToT) entre otros.
- Las herramientas: son los puntos de contacto con el mundo exterior, que permiten a los agentes interactuar con API, bases de datos u otros sistemas. Las herramientas amplían las capacidades de un agente más allá de la generación de texto, permitiéndole obtener datos en tiempo real o realizar acciones.
- La capa de orquestación: es un proceso cíclico que rige la forma en que un agente procesa la información, razona y decide las acciones. Es el nexo de unión entre el modelo y las herramientas (u otros agentes), asegurando que el agente progrese hacia su objetivo.
Con este enfoque estructurado del razonamiento, es posible abordar la ejecución de tareas que imiten la resolución de problemas humanos, basando las decisiones en información obtenida en tiempo real.
A grandes rasgos, el proceso de la capa de orquestación se encarga de
- Entrada: Recibir una consulta del usuario o datos de contexto.
- Razonamiento: Usar frameworks para planificar el siguiente paso.
- Acción: Generar respuestas o ejecutar tareas a través herramientas.
- Ajuste: Perfeccionar en función de los resultados.
Si pedimos información de un vuelo de Barcelona a Munich, se debería:
- Interpretar la entrada y el contexto anterior.
- Decidir que API usar de las que tenga disponibles (quizá tiene para consulta de hoteles, alquiler de coches…).
- Incluir los datos necesarios en la API, basándose en las interpretaciones de la entrada.
- Recuperar y procesar las opciones de vuelo para la respuesta, teniendo en cuenta posibles consideraciones de la entrada o de procesamientos anteriores.
Conexión con el mundo real
Hemos comentado que el poder de los agentes reside en su capacidad de hablar con el mundo real y sentirlo, pero ¿cómo lo hacen? Para conseguir esto, podemos basarnos en varias opciones entre las que destacan:
- Extensiones: son puentes estandarizados a las API, que permiten a los agentes ejecutar llamadas de forma dinámica. Por ejemplo, una extensión de Google Flights permite a un agente obtener datos de vuelos sin necesidad de una lógica de análisis personalizada.
- Funciones: fragmentos de código ejecutables del lado del cliente generados para el modelo. Con este mecanismo podemos tener mayor control de llamadas a terceras fuentes o gestionar llamadas asíncronas.
- Almacenes de datos: repositorios de datos estructurados o no estructurados (por ejemplo, PDF, sitios web) convertidos en datos vectoriales para acceso en tiempo real.

Con estas herramientas, los agentes pueden realizar tareas como actualizar bases de datos, obtener datos meteorológicos o recomendar itinerarios de viaje usando datos actualizados, mucho más allá de lo que un modelo fundamental puede hacer por sí solo.
Retrieval Augmented Generation (RAG)
Una de las aplicaciones más potentes de los almacenes de datos es la generación aumentada de recuperación (Retrieval Augmented Generation, RAG), una técnica que mejora el conocimiento de un agente con datos externos actualizados. Los modelos tradicionales son como bibliotecas estáticas: vastas pero congeladas en el tiempo de los datos que se usaron para su entrenamiento. Gracias a RAG podemos integrar la recuperación de datos en tiempo real.
Así es como funciona la RAG dentro de un agente:
- Un modelo de incrustación (embedding model) convierte una consulta de usuario en representaciones matemáticas.
- Estas incrustaciones se comparan con una base de datos vectorial (por ejemplo, utilizando el algoritmo SCaNN de Google ) que contiene datos preindexados de fuentes como sitios web, PDF o CSV.
- Se recupera el contenido relevante y se introduce en el modelo del agente.
- El modelo combina estos datos recuperados con la consulta para generar una respuesta o acción.
Así, para actualizar las respuestas, solo se deben actualizar las bases de datos vectoriales sobre las que realizamos las consultas, lo que es mucho más rápido y menos costoso.
Podemos imaginar a un chat de atención al empleado encargado de responder a la pregunta «¿Cuánto tiempo tengo de baja por maternidad?». Sin RAG, podría adivinar basándose en los datos de entrenamiento que pueden ser convenios anteriores. Con RAG, podemos buscar en un almacén de datos de archivos PDF de la empresa, recuperar los términos exactos y responder con precisión. Esta base en datos reales reduce las alucinaciones y aumenta la fiabilidad, algo crucial para las aplicaciones empresariales.
Otros ejemplos
Imaginemos que somos hinchas del Real Madrid y queremos ir a ver el partido de cuartos la Champions League en el estadio del equipo contrario. Así, podemos preguntar «Quisiera ir a ver el siguiente partido de cuartos de final del Real Madrid en la Champions League. ¿Cuál es la mejor manera de llegar al estadio? Si es en otra ciudad, dame la mejor opción de viajes partiendo desde Madrid y alojándome cerca del estadio». Aquí tenemos una consulta en varias etapas:
- Saber quién es el contrincante del Real Madrid
- Saber cuándo y dónde es el partido
- Si es en otra ciudad, obtener maneras de llegar allí y opciones de alojamiento
- Obtener ruta desde el alojamiento hasta el estadio
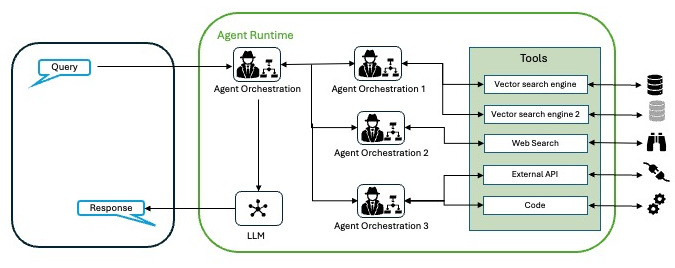
Para este caso, la implementación ideal sería un multiagente. Podemos usar una herramienta de búsqueda para los puntos 1 y 2 (SerpAPI por ejemplo) para obtener los últimos resultados para saber quien es el rival y cuándo y dónde será el próximo partido. A partir de ahí, podemos basarnos en algún almacén de datos, o en Google Maps, o en otras API para obtener las mejores maneras de llegar hasta el estadio en cuestión en esas fechas, añadiendo alojamiento si fuera necesario. Todo ello lo podemos orquestar, por ejemplo, con frameworks como LangChain y ReAct u otros.
En el caso de una empresa, podemos preguntar aspectos de operaciones o logística o atención al cliente…, basando las respuestas en documentos indexados o bases de datos externas. Por ejemplo, preguntar sobre las ayudas para aprender idiomas en la empresa y obtener la respuesta basándose en información actualizada que se encuentra en documentos PDF del departamento de Recursos Humanos.
Desafíos y Consideraciones
Como todo, a pesar de sus numerosas ventajas, la implementación de agentes de IA también presenta desafíos:
- Ética y Privacidad: Es crucial abordar las preocupaciones éticas y de privacidad asociadas con el uso de IA, especialmente en lo que respecta al manejo de datos sensibles. Si se da acceso a datos que deberían ser privados, podemos encontrar que aparezcan como parte de respuestas a alguien que no debería conocer esa información.
- Integración con Sistemas Existentes: La incorporación de agentes de IA en infraestructuras tecnológicas existentes puede requerir inversiones significativas y cambios en los procesos. Además, no hay que olvidar el punto anterior, no todo el mundo puede acceder a toda la información.
- Capacitación y Adaptación: Las organizaciones deben invertir en la capacitación de su personal para trabajar eficazmente junto a los agentes de IA.
El futuro de los agentes
Ya hemos visto que los agentes no se limitan a responder preguntas, sino que resuelven problemas, actúan en el mundo y se adaptan en tiempo real. Como se señala en el informe técnico de Google titulado Agents, solo estamos arañando la superficie. Los avances en el razonamiento (por ejemplo, los marcos híbridos CoT-ToT) y la sofisticación de las herramientas permitirán a los agentes abordar problemas aún más complejos. El concepto de «encadenamiento de agentes» o arquitectura de multiagentes, que consiste en vincular agentes especializados en una «mezcla de expertos», promete soluciones a medida en todos los sectores, desde la sanidad hasta las finanzas.
2 thoughts on “Agentes IA”