For a long time, organizations and entities have been storing data for further processing and obtaining information, but what does data imply in decision making? What are the most important data for organizations? How much is it worth? Let’s take a short walk through the world of data.
The importance of data in decisions
Life is made of decisions, the clothes we wear in the morning, what to eat, the mortgage to hire, whether to change jobs or not; some simpler and others much more difficult, and to determine the best option, our brain weighs countless information as variables, some with great certainty and others with total uncertainty, without overlooking that past experiences are also taken into account when conditioning future decisions, sometimes voluntarily and sometimes not.
Let’s suppose we are looking for information to buy a car, we like to look at its characteristics and compare them with other cars, some such as trunk capacity or horsepower, are objective measures that are easy to compare (not to weigh), but we will also take into account other more subjective aspects such as previous experiences of that brand, what we have heard, we will even take into account assumptions such as forecasts of what it may cost us to maintain it. We use information to decide which car is the most convenient for us and the one that will bring us the most value. But what does “the one that will bring us the most value” mean? According to its definition, value is “the degree of usefulness or fitness of things to satisfy needs or provide well-being or delight”. In the case of a car, the value for one person may lie in the fact that it can be easily parked because it is small, and for another in the fact that it has seven seats because he is a large family, or that it is fuel-efficient. The value given to each variable (and therefore to each car) will depend on each person and each moment.
In the case of organizations, the situation is similar. When a decision is to be made, the ideal is to have complete knowledge of the variables, the context in which the decision will be based and its possible consequences, and for this we need reliable data. To remain competitive, organizations must avoid making decisions based on intuition or hunches and apply analytics to their data in order to get a true picture of the situation and be able to make decisions based on accurate and current information.
On the other hand, the VUCA (Volatility, Uncertainty, Complexity, Ambiguity) environment in which we find ourselves, coupled with the pace at which business is being conducted, has made digital disruption the general rule rather than the exception and requires agile and dynamic decision making. This context drives business people to work closely with data management and exploitation teams to create solutions that help them make decisions and support business strategy, while exploring the growth possibilities that available data can offer, giving rise to new business models. Data-driven organizations are aware of this and have adapted to structure their processes and systems around data, thus being able to leverage them for decision making. But decisions are not made directly on the data; it must be processed beforehand.
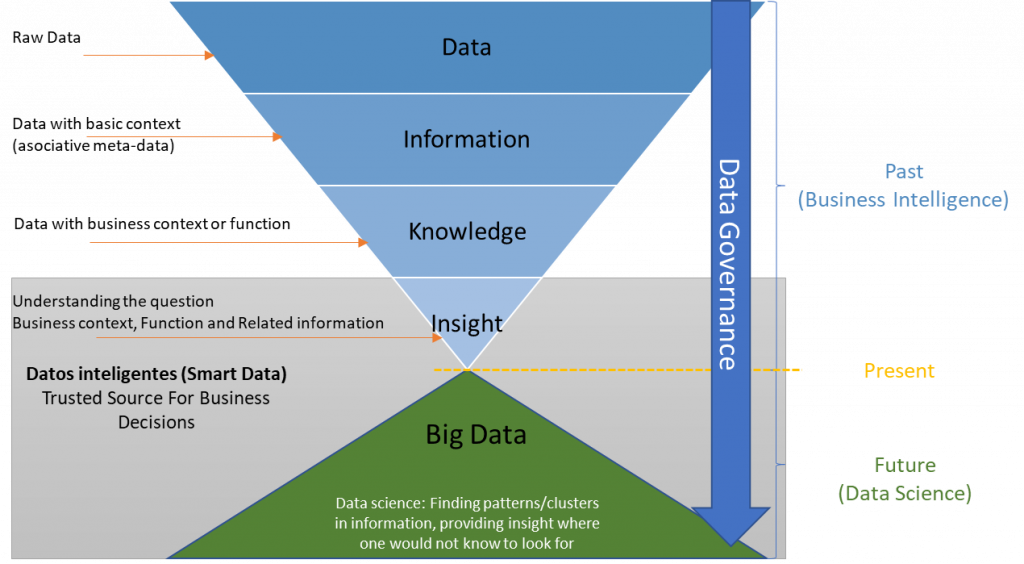
If we look at Abate’s information triangle, it is through data the way we can get basic information, from this information we get knowledge applying it to a certain business context or function, and from knowledge we get the insight that will help us understand and answer questions about our present; in the same way and thanks to Big Data, we can use data science to try to glimpse the future and get forecasts and prescriptions, which is where the real value is; but it all comes from the same source: data.
The value of data
We have already seen the importance of data for decision support, but not all data is equally valuable, so which data should we store?
Long gone are the punch cards and storage capacities of the 1890s, and storage capacity has increased dramatically in recent years, as has the drop in price. In 1956, the IBM 350 was a hard disk that occupied the size of a closet and could store 3.75 Mb at a cost of more than 3000 dollars per month; 8Mb flash drives in 2000 cost around 30 dollars and now for less than that price we can find 2Tb storage, that is, for the same price, 250,000 times more storage than in 2000. If we add to this reduction, the almost infinite capacity of cloud storage, it means that we can store an immense amount of data at a very low cost. But we should not be tempted to simply store for the sake of storage, because there are costs associated with this storage that must also be taken into account, such as all the processes of data acquisition, cleaning or processing, not to mention hidden costs such as data leaks or security risks. It should not be forgotten that data will be useful when it is used, not when it is simply stored. So what should we store, and for how long? Well, it will depend on the value that each data represents for the organization.
Let us take value as the difference between the cost of a thing and the benefit derived from that thing, i.e., we are interested in quantifying both the cost and the benefit of it. In some situations calculating the value is simple, as could be the case of a company’s shares, which would be the difference between the cost of the purchase and the benefit of the sale, but in the case of data it is not so simple, since neither the cost nor the benefit is standardized, so it is more difficult to determine its real value for the organization.
We must take into account that data are unique for each entity and their value may vary according to the context, this means that what is very valuable for an organization, may have no value for another, for example, a company that sells baby clothes will be very interested in knowing the number of children that a person has and their ages, while this data may be irrelevant for a company that is dedicated to deliver fuel. On the other hand, a piece of data can be relevant at one moment in time, but totally irrelevant after a while, such as promotional or seasonal campaigns, or even grow in value over time, as could be the case with data related to a customer placing orders, in other words, the value of a piece of data for an organization may not be fixed over time.
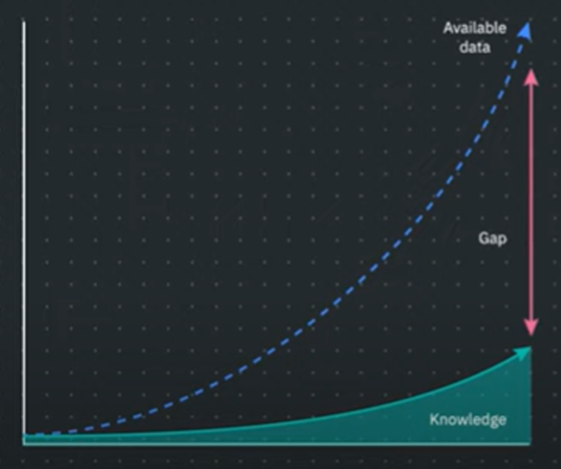
The cost of keeping data in our systems may be more or less easy to obtain, but we must also take into account the processes inherent to the creation and custody of that data, such as extractions, transformations or cleaning, among others. By this I mean that it may seem interesting a priori to store any type of data, but before applying management and security processes to it, the real value of such data for the organization or the risk of its leakage must be taken into account. As part of the data management strategy is to identify those entities that are important for the business and focus efforts there and not to lose focus by spending energy and resources in processing data that do not add value to the organization, because there are many more data available than data that we can process to obtain knowledge.
But again, what are the data that really add value to the organization? One way to start valuing a data economically can be to value the lack of it, i.e. what I have to pay in penalties or how much I can stop earning if I do not have that data; for example, if a company makes a profit of 10M€ per year from campaigns sent to emails, it means that the email addresses for that company are a data without which it could not receive this profit. It is more difficult to value data that allow us to infer future knowledge.
This leads us to the fact that, in data management, a fundamental step is to establish ways of associating a financial value to the data, this value will depend on each organization, and some ways of measuring it may be by market value, replacement cost, risk cost (of loss, lack, subtraction), sale of the data, etc.
What is clear is that, by associating a value to the data, we will be able to make strategic decisions about the data based on financial terms, this will not only help to give value to the data management activities but also to make the organization aware of the value of them, the financial impact on the company that they have and all the activities that are carried out for their management.
Data as an organizational asset
We know as assets for the company the set of goods, rights and other resources owned by a company, for example, furniture or computer equipment, also including those from which we expect to have a future benefit, i.e., everything that adds up in its favor.
In the case of data and from what we have seen so far, it is an intangible asset that meets the necessary attributes dictated by the International Accounting Standard (IAS) to be classified in this way, such as the ability to be identifiable (possibility of being isolated and sold) or the likelihood of generating future economic benefits in the form of income, cost reduction, etc. But it is a very peculiar asset, given that despite meeting the attributes of an intangible asset, it is not an asset from the accounting point of view, it does not appear in the P&L (although it is possible that we will see it in the future). Another peculiarity is that it is easily replicable and ubiquitous, we can have multiple copies in different places at the same time and replicate it indefinitely, with the risk that this also represents (as we will see later), because replication is also almost immediate. On the other hand, it is an asset that no matter how much we use it, it does not suffer wear and tear, it is an asset that can be used in different ways, at the same time and without deterioration; it is clear that data is a special asset. It should be clarified that if the data is not valid in the context of the business, or if it does not allow us to obtain reliable knowledge about it, it is nothing more than a disconnected value and can even lead us to wrong decisions, which is why due to the exponential increase of available data and the need to obtain knowledge and value from them, data management is becoming increasingly important, helping us to turn data into an asset of the organizations, but not just any asset, but a strategic one on which to support business decisions.
Data risks
Data is not only an asset for organizations, but can also become a risk if not well managed, let’s look at some cases.
The use of a piece of data can be a risk if its quality is not as expected (it may be incomplete, obsolete or inaccurate) because it can lead us to take erroneous strategic decisions. Sometimes it is better to have no data than to have bad data. Going back to the car simile, if we don’t know the length of the car, we can try to find it out in some other way, but if we have this data, we trust it and it turns out to be wrong, we could buy a car that does not fit in our parking space; we have made a wrong decision based on a piece of data that was not correct and the result is not as expected.

In terms of quality, we can also assess what we consider quality data, we could say that we have quality data if they meet the expectations and needs of users, but this in turn has many interpretations because expectations are different for each user and situation; so in general we could say that quality data must be complete, accurate, consistent, relevant, understandable, usable, meaningful and available when needed, so it is important that the data quality assurance processes are integrated and aligned with the processes of the organization.
The lack of data can impact the organization in different ways, for example, for making an important decision, a lack of data would be the difference between what we know and what we need to know to make an effective decision, but if we have a court order or an audit, the lack of data can directly affect the finances and reputation of the organization for not complying with regulations or laws that apply in that business or region. On the other hand, a piece of data can be misinterpreted or misused, so it is very important to manage the metadata related to the data correctly, so that anyone who uses a piece of data can know the optimal way to use it, what it means, where it was obtained from or be aware of other complementary data to it.
With all we have seen above, it is clear that in order to be able to offer reliable and trustworthy data with the necessary security in the required time, data management professionals must better understand the requirements of what quality means for their clients (the stakeholders to whom the data will offer value) and how to measure this quality to improve it, likewise, having an architecture and infrastructure to govern and manage data in a way that offers value to the organization, is key to be able to offer the data in the aforementioned conditions. We can see that the work to be done is not trivial and involves a process of technological and cultural transformation in companies; but we are not alone, organizations such as DAMA provide us with tools and publications to help us in these tasks.
2 thoughts on “Data, data and more data”