We have all heard about LLMs (Large Language Models) and how they are capable of holding conversations, providing a wide variety of information, and being truly creative. For example, we can ask ChatGPT for a meringue recipe, to write a poem about a cat in space, or to explain how a jet engine works to an elementary school student. This is incredibly powerful, but it is not all advantages. The truth is that these models come with high costs and, in many cases, slow response times that can annoy users. This is largely due to the number of parameters that are evaluated in each request, which has a computational cost in terms of time and money.
But if we only want it to answer questions about company regulations, do we need the model to know how to answer our questions about the afterburning of jet engines? With the emergence of AI agents, we can divide tasks and use models that specialize in that single task. A couple of months ago, Nvidia published a very interesting paper on SLMs (Small Language Models) and how they could be the solution for the future.
What is a Small Language Model?
Let’s start by talking about LLMs, which, to simplify, we can say are little brains that learn from tons of books, websites, and conversations to answer questions, write stories, or even program. We can think of them as an employee who has read everything on the internet and can talk about anything because he retains everything. And what makes him so capable? The parameters.
Parameters are like the “neural connections” that form the core of an LLM. Technically, they are numbers, mathematical values that the model adjusts during training to ‘remember’ and “understand” information. We can think of LLMs as a giant mind map. Each parameter is an intersection on that map that connects ideas, words, or concepts. An LLM with more parameters has a more detailed and complex map. In general, we can say that having more parameters allows the LLM to handle more complex tasks, such as logical reasoning, language translation, or code generation. In other words, parameters serve to make the model “smarter” and less prone to errors. (Note: we should not rely on the number of parameters to determine whether one model is better than another. Models with fewer parameters typically outperform models with more parameters from previous generations. For example, Llama 3 with 8B parameters scores 68.4 on MMLU, while Llama 2 with 13B parameters only scores 54.8.)
But it’s not all advantages. More parameters mean that it costs more to train, debug, and run, in other words, greater energy and computational expenditure; higher costs. To give you an idea, GPT-3 has 175 billion parameters, Llama 2 has (in one of its versions) 176 billion, and GPT-4 is rumored to have over 1.76 trillion parameters. That’s a lot of parameters to train and consult.
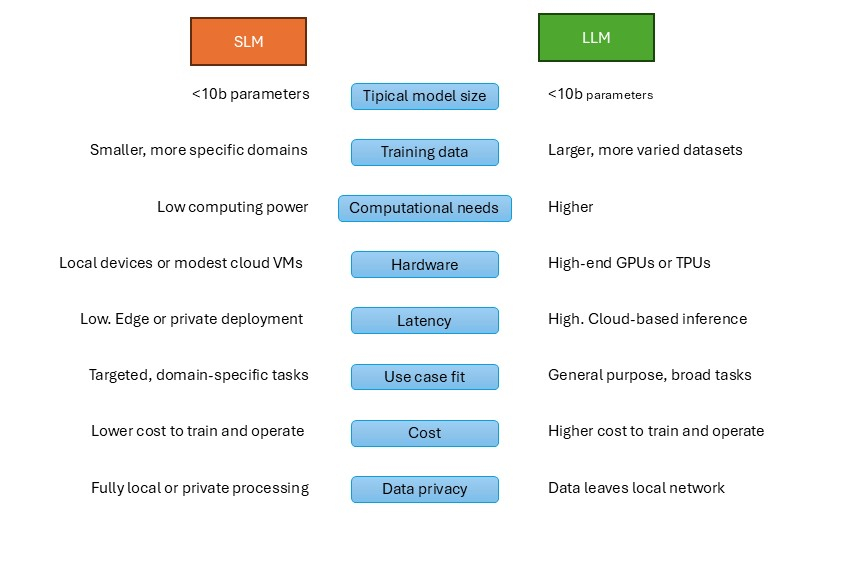
SLMs are also natural language models, but they are smaller in size, typically between 100 million and a few billion parameters. Generally speaking, SLMs can be considered models that fit into common consumer devices (less than 10B parameters in 2025) and can infer with low latency, sufficient for a user.
SLMs emerged in response to the aforementioned challenges of Large Language Models (LLMs), such as high energy consumption and training and execution costs. Using techniques such as knowledge distillation (where a large model “teaches” a small one in a summarized way) and quantization (an optimization technique that reduces the numerical precision of AI model data), models are obtained that “maintain” performance while reducing size. “Maintain” is in quotation marks because the models actually degrade in one way or another, but depending on the purposes for which we need them, they are more than valid.
SLMs will allow us to run models on local devices without relying on the cloud, which makes them particularly interesting when it comes to reducing costs and maintaining privacy.
There are multiple SLMs available, for example:
- Microsoft Phi-3: With 3.8 billion parameters, it is one of the most efficient. Trained on high-quality synthetic data, it excels in reasoning and code. It can even run on a smartphone with only 4GB of RAM. (link)
- Google Gemma: Based on Gemini, it has 2B and 7B parameter versions. It is lightweight and versatile for tasks such as translation and text summarization. (link)
- Meta Llama 3 (small version): With 1B parameters, it is an evolution of Llama 2. It supports multiple languages and is ideal for chatbots. (link)
But these are not the only ones; there are many more that we can easily try on our computers using software such as Ollama, LMStudio, or Jan AI, among many others.
SLMs vs. LLMs
There are several differences between SLMs and LLMs, but we can summarize them as follows:
- Size and Resources: SLMs use 10-100 times fewer parameters, reducing training from weeks to days. If an LLM consumes energy equivalent to a household per hour of use, an SLM would be like an LED light bulb.
- Performance: In benchmarks such as GLUE or MMLU, SLMs such as Phi-3 achieve 70-80% of the score of LLMs in simple tasks (text classification or basic Q&A), but fail in complex reasoning. It should also be noted that with fine-tuning, they close this gap considerably.
- Speed and Cost: SLMs infer answers in milliseconds on modest hardware (using CPUs, not expensive GPUs).
- Privacy: In the case of SLMs, the data does not leave the device, while with LLMs we depend on the computing power of the cloud, having to move the data there.
- Contexts: SLMs handle smaller, less generalized contexts, while LLMs handle much larger contexts. An SLM can have contexts of about 8k-32k tokens, while an LLM such as GPT4 can have contexts ranging from 128k to over a million tokens.
We could say that SLMs are “lightweight AI” for the real world, while LLMs are for advanced research, as discussed in the Nvidia paper.
Is this the future of SLMs?
According to reports by Gartner, by 2025, 75% of enterprise data will be processed at the edge, driving this technology forward.
It is clear that LLMs are larger and depend on cloud infrastructures that are much more complex to maintain and evolve (with all that this entails), but the key question is whether SLMs are capable and versatile enough to provide real value, as LLMs do. In this regard, the authors argue in the paper that SLMs are:
- Powerful enough for agent-based applications: With advances in training, SLMs such as Microsoft Phi-3 (7B) or NVIDIA Nemotron-H (4.8B) match or surpass previous-generation LLMs in reasoning, code generation, and tool calls, with up to 15x faster speed. For example, DeepSeek-R1-Distill (7B) outperforms Claude-3.5 in reasoning.
- More operationally suitable: AI agents work with complex tasks broken down into simple subtasks, where SLMs shine due to their flexibility and adaptability to heterogeneous systems (mixing SLMs and LLMs).
- More economical: 10-30x cheaper inference in latency, energy, and FLOPs. In addition, fine-tuning can be performed more quickly (hours vs. weeks) and deployed at the edge (local devices), reducing costs and improving privacy.
In 2025, surveys such as Cloudera’s indicate that 96% of companies are addressing AI agents, with a market worth $5.2 billion growing to $200 billion by 2034. Here, SLMs offer concrete advantages:
- Economic efficiency: Due to the economic efficiency of SLMs, for companies with high query volumes (e.g., chatbots in e-commerce), the use of SLMs can reduce OPEX by 50-90% (according to McKinsey’s analysis of generative AI). Being able to deploy at the edge avoids dependence on expensive cloud infrastructure.
- Flexibility and adaptability: SLMs can be quickly adapted through fine-tuning to perform specific tasks, such as data analysis in IoT or route optimization in logistics. With SLMs, more companies can create customized models, fostering innovation without barriers to scale.
- Sustainability and compliance: Lower energy footprint and alignment with regulations such as GDPR (keeping data local).
But not everything is ideal for SLMs. LLMs have better overall semantic understanding, and depending on how they are used, economies of scale could occur in the cloud, making their inference cheaper in the long run.
On the other hand, we have already seen that SLMs perform well when given specific tasks, which means that they could fail at tasks that are not broken down, which an LLM could handle correctly. In other words, SLMs are more prone to failure when there are variations. In an open conversation where any topic can be discussed, an LLM is likely to perform better.
In my opinion, SLMs are the future… with some caveats. I believe that SLMs will be the future for most companies that use AI agents; the empirical evidence is that SLMs already rival performance while drastically lowering costs in many tasks. On the other hand, they democratize AI, making it possible for SMEs to work with their own models and adjust them to their needs without depending on large companies such as Microsoft or Google.
But then there are the nuances; it’s not “all or nothing.” I believe that the future will be hybrid systems: SLMs for 80% of repetitive tasks (e.g., data processing in the supply chain), LLMs for the creative 20%. Through hybrid systems, we can use SLMs for daily routines and LLMs only for complex tasks, optimizing resources.
Time to try SLMs: savings and greener AI.