As part of the Collins dictionary we can find the word kafkaesque with the following meaning “of, characteristic of, or like the writings of Kafka; specif., surreal, nightmarish, confusingly complex”.
In the world of technology, where sometimes there are absurd or distressing situations, Kafka may be the solution to our problems.
Apache Kafka is an open source distributed event streaming platform. It is a high-performance solution for handling real-time event (data) streams. It was developed by LinkedIn and later became part of the Apache Foundation project. With the proliferation of event-driven systems, Kafka is taking a relevant role as a solution for both simple and complex cases.
The uses of Kafka in modern applications are wide-ranging, from collecting logs and metrics, to feeding real-time recommendations, to tracking user activity on websites.
Kafka has certain features that make it stand out as a solution for real-time event processing, for example:
- High performance: Kafka can handle millions of events per second, making it ideal for high-volume applications.
- Scalability: Kafka can scale horizontally to handle even more events by simply adding more nodes to the cluster.
- Durability: Events in Kafka are stored on disk and replicated within the cluster to prevent data loss.
- Real-time: Kafka enables real-time event processing, which is crucial for many modern applications.
The topic of Apache Kafka is broad enough to cover several books, from learning about the various implementations or system administration to advanced programming.
But let’s dive a little deeper to learn more about how it works.
Kafka Basics
To understand how Kafka works, it is helpful to become familiar with some of its key concepts:
- Events: An event is a record or message that is sent to Kafka. Each event consists of a key, a value and a timestamp.
- Topics: Events are grouped into categories called topics. A topic is an ordered and immutable sequence of events that are distributed among several files.
- Producers: Producers are the entities that publish data in Kafka topics.
- Consumers: Consumers read events from Kafka topics.
- Connectors: Connectors are an interface that allows Kafka to connect to external systems to import or export data.

How does it work?
Kafka is based on the publish-subscribe model, where producers send messages to a topic and consumers subscribe to one or more topics to receive the messages.
The main steps of how Kafka works are as follows:
- Creating a topic: A topic is a category or logical name that groups messages that have a common purpose or meaning. A topic is divided into partitions, which are independent storage units containing the messages. Each partition has a sequential order and a unique identifier. To create a topic, you can use the command line tool kafka-topics.sh or the Kafka Administration API. For example, to create a topic named test with 3 partitions and a replication factor of 2, you can run the following command:
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 3 --topic test- Message production: A message is a unit of data that is sent to a topic. A message consists of a key, a value and an offset. The key is used to determine to which partition the message is assigned, the value is the content of the message and the offset is a number that identifies the position of the message within the partition. To produce messages, you can use the command line tool kafka-console-producer.sh or the Kafka producer API. For example, to send messages to the test topic from the console, the following command can be executed:
kafka-console-producer.sh --broker-list localhost:9092 --topic test- Message consumption: A consumer is an application that reads the messages of one or more topics. A consumer can be assigned to a consumer group, which is a set of consumers that cooperate to consume messages from a topic. Each partition of a topic is assigned to a single consumer within a consumer group, and each consumer can consume from one or more partitions. To consume messages, the command line tool kafka-console-consumer.sh or the Kafka consumer API can be used. For example, to consume the test topic messages from the beginning, the following command can be executed:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning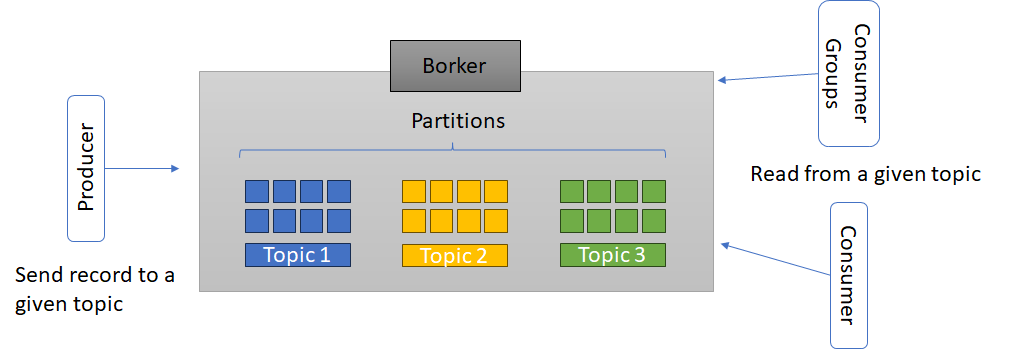
This is a short introduction that I hope has helped the reader to learn how Kafka can help decouple functionalities and make systems highly scalable and has also whetted the reader’s appetite to learn more about Apache Kafka.