Maybe because of the image someone thinks that we will talk about special agents like 007, but no, we will talk about other types of agents. More or less people use generative AI in their daily lives. Perhaps one of the biggest problems we have encountered when using it is that, on occasions, we come across models or chats that cannot provide us with updated information, i.e. we cannot ask about things that have happened in the near past, such as who won the F1 race last weekend. For example, the Generative Pre-trained Transformer 3.5 (GPT-3.5) model was made public on March 15, 2022 and was trained with data available from certain sources until June 2021. This means that the chat would not be able to respond correctly to anything occurring after June 2021.
The reality is that to train a model, it takes quite a long time and requires a large amount of computing resources, so it is not possible to be training the model every minute to provide fully updated information.
To overcome this problem and extend the capabilities of traditional language models, agents have emerged.
Unlike stand-alone models limited by their training data, agents combine reasoning, external tools and access to real-time data to tackle complex tasks autonomously. Large language models (LLMs) are static, limited to their training data, and typically provide one-turn (context-aware) responses. Agents, however, manage session history, use tools natively, and employ reasoning frameworks to handle complex interactions that may incorporate multiple steps. For example, a model might answer “What is the weather today?” based on its training, and most likely hallucinating outdated information. If we have agent equipped with a weather API tool, we could obtain real-time data and provide an accurate, up-to-date response. This ability to expand knowledge and act dynamically makes agents a cornerstone for practical applications.
In essence, generative AI agents are applications designed to autonomously achieve specific goals by observing their environment (and acting on the environment) using a set of tools.
These agents go beyond simple natural language processing (which generate responses based solely on preconceived knowledge), encompassing capabilities such as decision making, problem solving and interaction with external environments. We can think of them as digital assistants that not only understand the request, but can also obtain real-time information, interact with APIs or even execute tasks such as sending emails or controlling systems, all without constant human supervision.
We can describe the agents with the following architecture.
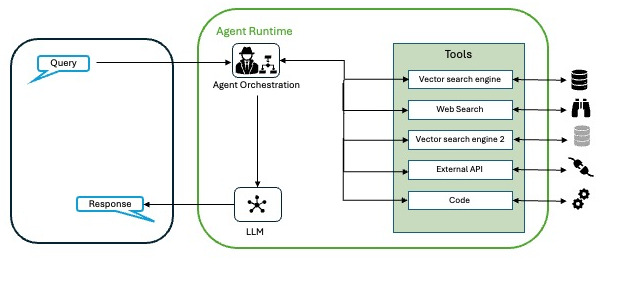
- The model: it is the language model (LLM) that acts as the brain for decision making. It can be a single model or a combination of models (small or large, general purpose or tuned) capable of following reasoning frameworks such as Reason and Act (ReAct) , Chain-of-Thought (CoT) or Tree-of-Thoughts (ToT) among others.
- Tools: are the points of contact with the outside world, which allow agents to interact with APIs, databases or other systems. Tools extend an agent’s capabilities beyond text generation, allowing it to obtain real-time data or perform actions.
- The orchestration layer: is a cyclic process that governs how an agent processes information, reasons and decides on actions. It is the link between the model and the tools (or other agents), ensuring that the agent progresses towards its goal.
With this structured approach to reasoning, it is possible to approach the execution of tasks that mimic human problem solving, basing decisions on information obtained in real time.
Broadly speaking, the orchestration layer process is responsible for.
- Input: Receiving a user query or context data.
- Reasoning: Using frameworks to plan the next step.
- Action: Generating responses or executing tasks through tools.
- Tuning: Refine based on the results.
If we ask for information about a flight from Barcelona to Munich, we should:
- Interpret the input and previous context.
- Decide which API to use from the ones you have available (maybe you have for hotel queries, car rental…).
- Include the necessary data in the API, based on the interpretations of the input.
- Retrieve and process the flight options for the response, taking into account possible considerations from the input or previous processing.
Connection with the real world
We have said that the power of agents lies in their ability to talk to the real world and feel it, but how do they do this? To achieve this, we can rely on several options among which the following stand out:
- Extensions: these are standardized bridges to APIs, which allow agents to execute calls dynamically. For example, a Google Flights extension allows an agent to obtain flight data without the need for custom analysis logic.
- Functions: client-side executable code snippets generated for the model. With this mechanism we can have more control over calls to third party sources or manage asynchronous calls.
- Data warehouses: repositories of structured or unstructured data (e.g. PDF, web sites) converted into vector data for real-time access.
With these tools, agents can perform tasks such as updating databases, retrieving weather data, or recommending travel itineraries using updated data, far beyond what a fundamental model can do on its own.

Retrieval Augmented Generation (RAG)
One of the most powerful applications of data warehouses is Retrieval Augmented Generation (RAG), a technique that enhances an agent’s knowledge with updated external data. Traditional models are like static libraries: vast but frozen in time of the data that was used for their training. Thanks to RAG we can integrate real-time data retrieval.
Here’s how RAG works inside an agent:
- An embedding model (embedding model) converts a user query into mathematical representations.
- These embeddings are compared against a vector database (e.g., using Google’s SCaNN algorithm ) containing pre-indexed data from sources such as websites, PDF or CSV.
- Relevant content is retrieved and fed into the agent’s model.
- The model combines this retrieved data with the query to generate a response or action.
Thus, to update the responses, only the vector databases on which we perform the queries need to be updated, which is much faster and less expensive.
We can imagine an employee service chat in charge of answering the question “How long am I on maternity leave?”. Without RAG, it could guess based on training data that may be previous agreements. With RAG, we can search a data warehouse of company PDF files, retrieve the exact terms, and answer accurately. This grounding in real data reduces guessing and increases reliability, which is crucial for enterprise applications.
Other examples
Let’s imagine that we are Real Madrid fans and we want to go to see the Champions League quarter-final match at the opposing team’s stadium. So, we can ask “I would like to go to see Real Madrid’s next Champions League quarter-final, what is the best way to get to the stadium? If it is in another city, give me the best travel option leaving from Madrid and staying near the stadium”. Here we have a consultation in several stages:
- Know who Real Madrid’s opponent is.
- Know when and where the match is
- If it is in another city, obtain ways to get there and accommodation options.
- Obtain route from the accommodation to the stadium
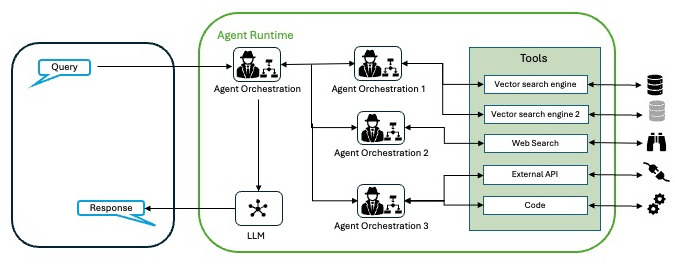
For this case, the ideal implementation would be a multi-agent. We can use a search tool for points 1 and 2 (SerpAPI for example) to get the latest results to find out who the opponent is and when and where the next match will be. From there, we can rely on some data warehouse, or Google Maps, or other APIs to get the best ways to get to the stadium in question on those dates, adding accommodation if necessary. All of this can be orchestrated, for example, with frameworks such as LangChain and ReAct or others.
In the case of a company, we can ask about aspects of operations or logistics or customer service…, basing the answers on indexed documents or external databases. For example, ask about language learning aids in the company and get the answer based on updated information found in PDF documents from the Human Resources department.
Challenges and Considerations
As with anything, despite its many advantages, the implementation of AI agents also presents challenges:
- Ethics and Privacy: It is crucial to address the ethical and privacy concerns associated with the use of AI, especially regarding the handling of sensitive data. If access is given to data that should be private, we may find that it appears as part of answers to someone who should not know that information.
- Integration with Existing Systems: Incorporating AI agents into existing technology infrastructures may require significant investments and process changes. Also, don’t forget the previous point, not everyone can access all the information.
- Training and Adaptation: Organizations must invest in training their staff to work effectively alongside AI agents.
The future of agents
We have already seen that agents are not just answering questions, but solving problems, acting in the world, and adapting in real time. As noted in the Google’s Agents white paper, we are only scratching the surface. Advances in reasoning (e.g., hybrid CoT-ToT frameworks) and tool sophistication will enable agents to tackle even more complex problems. The concept of “agent chaining” or multi-agent architecture, which consists of linking specialized agents in a “mix of experts,” promises tailor-made solutions in all sectors, from healthcare to finance.
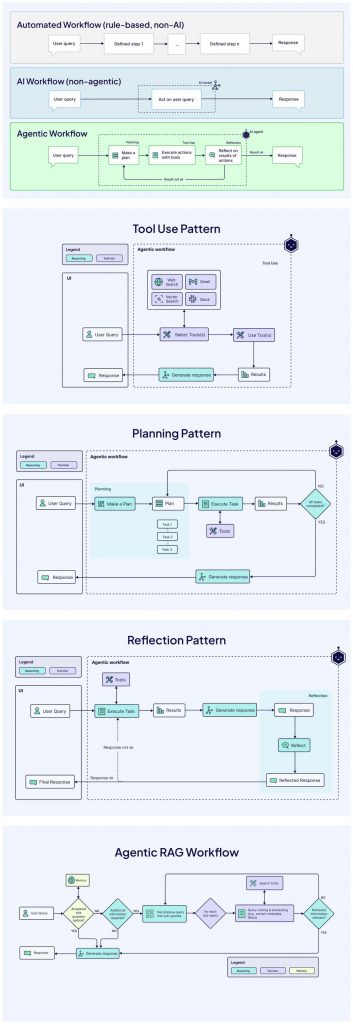
Interesting. We are really facing a revolution when it comes to doing tasks… and I’m not referring to the typical automation tasks, almost any job can be replaced!