En post anteriores hemos hablado de como los LLM (Large Language Model) están cambiando la manera en la que realizamos las tareas y de cómo pueden ayudarnos en todo tipo trabajos.
Hemos visto como a estos modelos genéricos se les puede dotar de contexto para que den una respuesta más ajustada y actual que la que darían con sólo su entrenamiento. También hemos visto que pueden interactuar entre ellos y utilizar herramientas externas con las que completar sus tareas.
Pero esto, ¿es complejo de llevar a cabo?. Como todo en esta vida, depende del contexto, la escala y el caso de uso. La buena noticia es que existen herramientas que nos ayudan a incorporar todas estas prácticas para ayudarnos a automatizar y controlar tareas. En este texto vamos a ser un poco más prácticos que teóricos y vamos a ver una de estas herramientas: n8n.
Antes de ir más en profundidad, ¿qué es n8n?
n8n es una solución que hace que la automatización con IA no sea un lujo al alcance de pocos, es una plataforma de automatización de flujos de trabajo de código abierto, no-code/low-code, que permite a las empresas optimizar procesos, integrar sistemas y por supuesto, aumentar la eficiencia. Dispone de una interfaz visual intuitiva y muy potente que se puede conectar a multitud de aplicaciones a través de API. ¿Lo mejor? que también podemos utilizar capacidades de IA a lo largo del flujo de trabajo mediante mecanismos comentados en posts anteriores como LangChain entre otros.
Quizá una de las mejores maneras de ver su potencial, es implementar un pequeño caso de uso, pero antes de nada, veamos como podemos tener disponible n8n para poder trabajar con ella.
Instalación
Como hemos comentado, n8n es un software de código abierto. Podemos trabajar con él usando la versión community que es gratuita o la enterprise de pago. En este caso trabajaremos con la versión gratuita. Del mismo modo, podemos optar trabajar con n8n de diferentes maneras:
- En un proveedor cloud que lo mantenga por nosotros (sin instalación)
- Self hosted, mantenido por nosotros mismos
- Incrustado en nuestros propios desarrollos
Para el ejemplo se ha utilizado una implementación self hosted en Docker, pero el ejemplo en sí, es igualmente válido para las otras opciones.
Lo primero será tener instalado Docker en nuestro ordenador. Una vez que tenemos Docker funcionando, podemos crear un volumen para almacenar datos y descargar e iniciar el contenedor con n8n:
docker volume create n8n_data
docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nTras unos instantes, podremos acceder al entorno de trabajo de n8n en la url http://localhost:5678
Caso de uso
Para ilustrar un poco mejor las capacidades que n8n puede ofrecernos, vamos a implementar un caso de uso.
Contexto: Somos una persona muy activa en redes sociales que trabaja en una empresa tecnológica y queremos escribir en LinkedIn sobre temas que sean de actualidad.
Resumen de la implementación: Como nunca sabemos cuando aparece la musa, vamos a tener una aplicación móvil donde le escribamos un tema y se lo enviaremos a n8n. El flujo de n8n se encargará de ver que tendencias hay sobre ese tema en concreto, buscando información en Google. Una vez conocidas las tendencias determinará cual es la mejor para escribir sobre ella y escribirá un post. El post se publicará directamente en LinkedIn.
Implementación
No vamos a ver cómo se realizaría la implementación de la aplicación móvil, sino que nos centraremos en el workflow directamente (en este caso, con vibe coding lo podríamos conseguir de manera sencilla 😉 ). Lo primero que debemos hacer es proporcionar un webhook de n8n al que llamar desde la aplicación móvil. Este webhook será el desencadenante de todo el workflow. En esta llamada enviaremos el tema sobre el que queremos obtener información de google y que estará ligado con el tema sobre el que escribiremos el post.
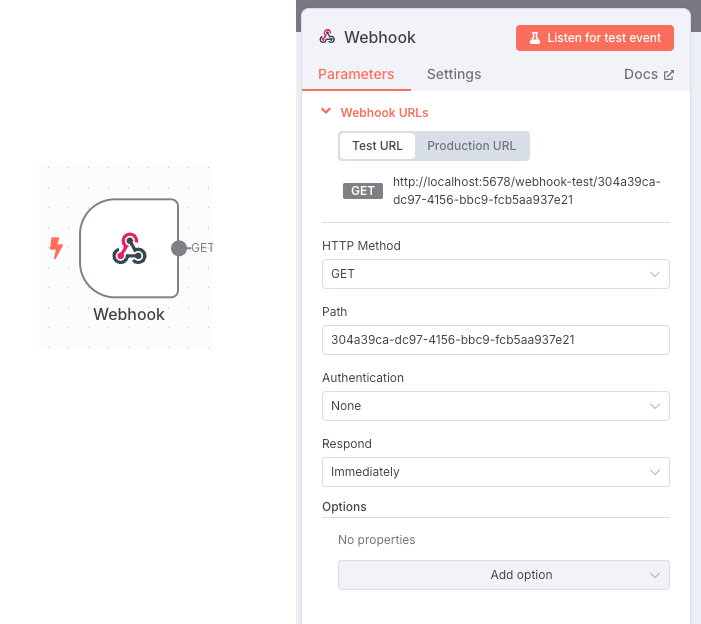
Como podemos ver, el elemento nos define la url a la que debemos enviar el tema a buscar. Ahora solo deberíamos pasar como parámetro este tema del que queremos conocer tendencias de búsqueda, por ejemplo en este caso queremos saber sobre inteligencia artificial, así que la llamada sería: http://localhost:5678/webhook-test/304a39ca-dc97-4156-bbc9-fcb5aa937e21?q=artificial%20Intelligence.
Podemos probarlo directamente desde el navegador. Una de las facilidades que nos da n8n es que permite probar cada paso del workflow de manera independiente y ver el resultado de su ejecución.
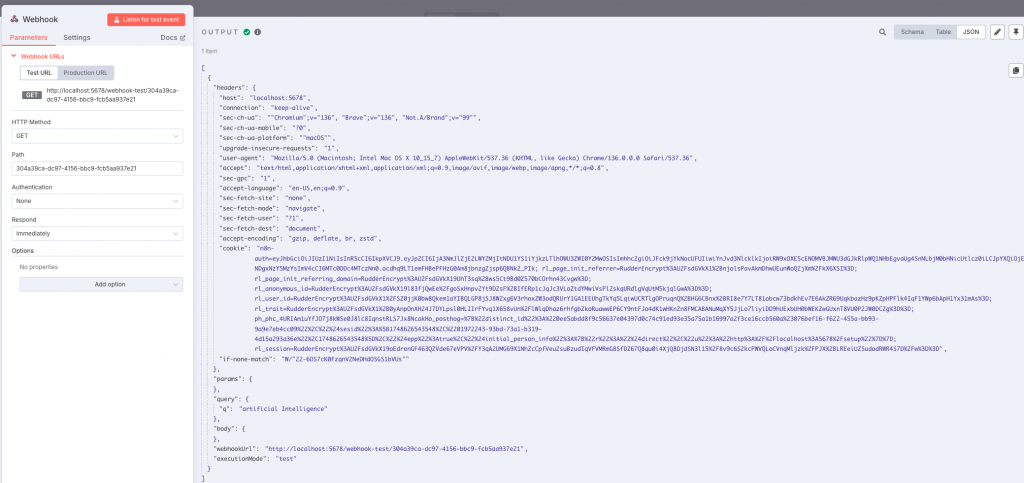
Una vez el workflow recibe la petición del tema a analizar, llamaremos a la API de Google para conocer cuáles son las preguntas que son tendencia en la ultima semana acerca de ese tema. Para ello necesitaremos llamar a https://serpapi.com/search con los parámetros correspondientes. Uno de los parámetros que necesitamos es el tema a buscar, que lo recuperamos del paso anterior mediante » {{ $json.query.q }}».
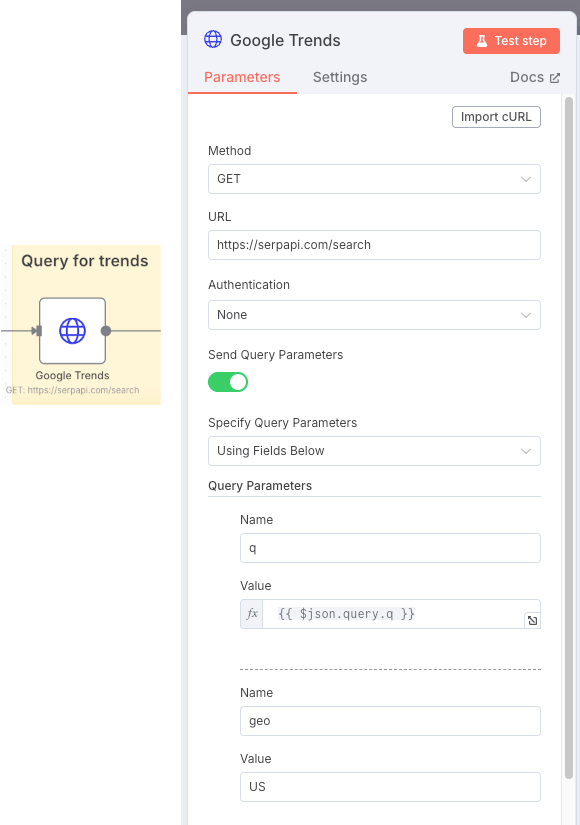
Al ejecutar este paso obtendremos las búsquedas más relevantes respecto al tema que hemos aportado como parámetro, tanto las más buscadas como las que más incremento de búsquedas han sufrido en esta última semana.
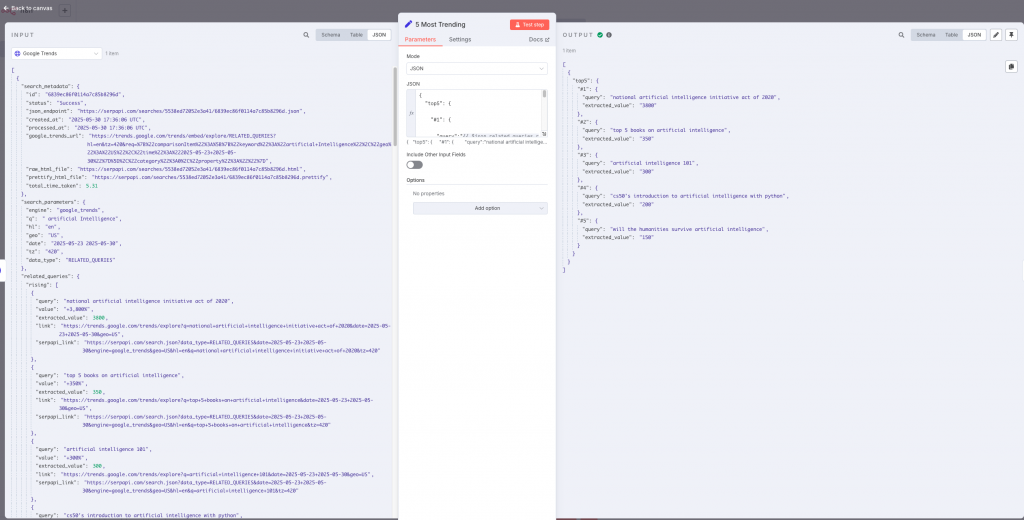
De la respuesta obtenida, filtraremos para quedarnos con las 5 más relevantes.

Mediante el siguiente código obtenemos las 5 más relevantes.
{
"top5": {
"#1": {
"query":"{{ $json.related_queries.rising[0].query }}",
"extracted_value":"{{ $json.related_queries.rising[0].extracted_value }}"
},
"#2": {
"query":"{{ $json.related_queries.rising[1].query }}",
"extracted_value":"{{ $json.related_queries.rising[1].extracted_value }}"
},
....
}
}
De las 5 búsquedas más relevantes, vamos a dejar que un modelo LLM escoja por nosotros la que más se ajuste a los temas que normalmente tratamos. Para ello añadimos un agente IA que nos facilite este trabajo. En este tipo de paso, podemos definir el modelo que queremos usar, si queremos que guarde memoria de las ejecuciones anteriores (indispensable en chats) e incluso las herramientas que pueden ayudar en el contexto. En nuestro caso solo usaremos el modelo LLM.
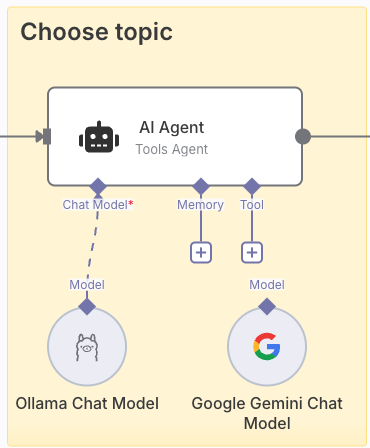
En el ejemplo se pueden ver dos modelos distintos, uno basado en un servicio de Google usando Gemini y otro usando un modelo en local usando Deepseek (o cualquier otro modelo) mediante Ollama. Con esto quiero poner foco en que si no queremos usar modelos externos (como sería Gemini) porque no queremos tener fugas de información, podemos usar nuestros modelos en local sin problema. Podríamos conectar indistintamente cualquiera de los modelos sin tener que variar el workflow.
Para que el modelo sea capaz de elegir entre las opciones obtenidas en el paso anterior, le vamos a decir mediante el prompt, cómo esperamos que se comporte y lo que esperamos de él. Algo como:
You are part of the editorial team of a technology and business company, your job is to choose interesting topics to post on LinkedIn.
Some of the posts are also posted in company's webpage. It is important that the entries are well positioned at SEO level.
You are provided with a list of keywords that have been the most searched for in Google during the last week.
Your job is to choose what you think would be the most relevant blog post with the best SEO results.
Keywords have two attributes:
1. query: this attribute marks the search query that users have performed and that is trending.
2. extracted_value: this attribute marks the percentage increase that the keyword has experienced compared to previous periods.
You should choose one taking into account both the keyword's relevance to the company's SEO efforts and the comparative trend determined by the “value” attribute.
Write the keyword you have decided to post about without reasoning. Just write the word. Don't explain your reasoning
For this case:
Keyword 1:
{{ $('5 Most Trending').item.json['top5']['#1'].toJsonString() }}
Keyword 2:
{{ $('5 Most Trending').item.json['top5']['#2'].toJsonString() }}
Keyword 3:
{{ $('5 Most Trending').item.json['top5']['#3'].toJsonString() }}
Keyword 4:
{{ $('5 Most Trending').item.json['top5']['#4'].toJsonString() }}
Keyword 5:
{{ $('5 Most Trending').item.json['top5']['#5'].toJsonString() }} Con ello obtendremos la entrada que según el modelo más se ajuste al perfil de nuestro prompt. Cada modelo puede actuar de manera distinta.
Una vez tenemos el tema para crear el post, le pedimos en este caso a Grok que nos escriba al respecto. Otra manera de llamar a LLMs.
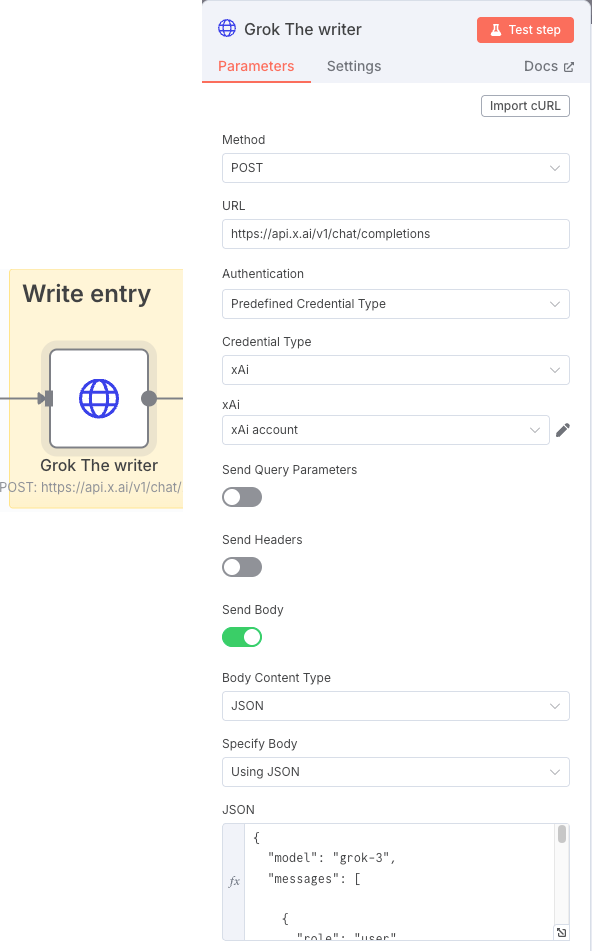
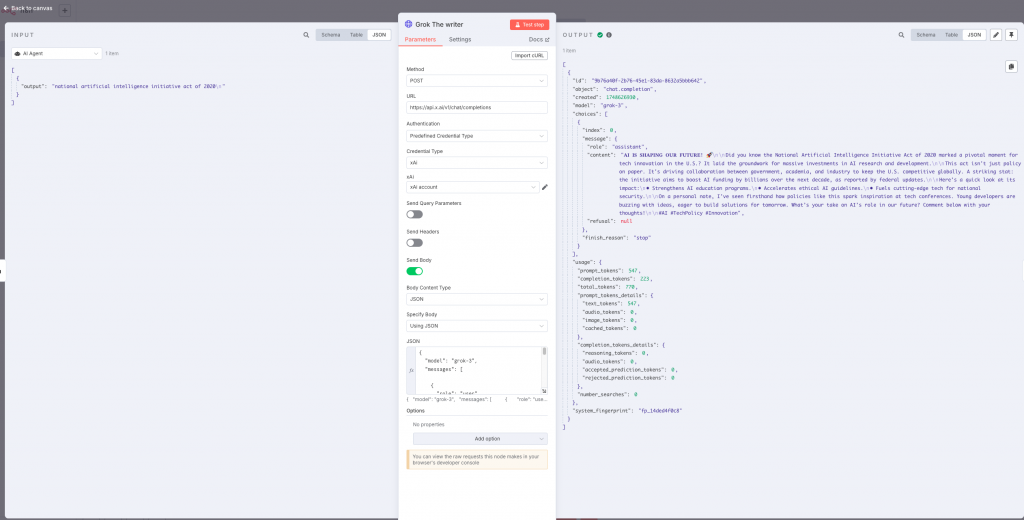
Nuevamente aprovecharemos para indicar mediante el prompt, cómo queremos que se comporte durante la redacción del post. Mediante las entradas «role» indicaremos la petición del usuario (user) y cómo debe tratarlo el sistema (system) a nivel de contexto y restricciones de la conversación. Esto lo indicamos junto al modelo en el apartado JSON:
{
"model": "grok-3",
"messages": [
{
"role": "user",
"content": "You are a business and technology insider and expert copywriter in a blog editor development team about technology and business. Generate exactly one LinkedIn post that is easy to read for humans and adheres to LinkedIn's API formatting guidelines. Follow these rules:\n\nStructure:\n1. Hook: Start with a bold opening line using Unicode characters (e.g., \"𝐁𝐎𝐋𝐃 𝐒𝐓𝐀𝐓𝐄𝐌𝐄𝐍𝐓\").\n2. Body: Use short paragraphs (1-3 sentences) separated by \\n\\n.\n3. Use bullet points (•) for key features or highlights.\n4. End with a clear call-to-action (e.g., \"Comment below with your thoughts!\").\n\nFormatting Requirements:\n- Remove all numeric citation brackets like [2], [3], [4] from the text.\n- Instead of citation brackets, if needed, add a brief phrase like \"according to Google I/O 2025\" or \"as reported by DeepMind\" naturally within the sentence.\n- No Markdown or rich text formatting.\n- Use Unicode characters or emojis for emphasis (e.g., ★, 🚀).\n- Include up to 3 relevant hashtags at the end (e.g., #AI #Automation).\n- Add URLs or references, for them use placeholders like [Link] instead of raw URLs.\n- If mentioning users or companies, use official LinkedIn URN format (e.g., \"urn:li:organization:123456\").\n\nContent Rules:\n- Max 1,200 characters.\n- Avoid promotional language.\n- Include one statistical claim or industry insight.\n- Add one personal anecdote or professional observation.\n\nReturn the post as plain text without additional commentary.\n\nInput: {{ $json.output.trim() }}"
},
{
"role": "system",
"content": "Act as a skilled editor revising AI-generated text to make it sound authentically human. Follow these rules:\n\n1. Punctuation Adjustments\n - Limit digressions in parentheses; integrate explanations into the main sentence. Language.\n - Eliminate ellipses in the middle of sentences, unless they mimic a deliberate hesitation.\n - Replace long dashes, semicolons, or rephrase sentences when nccessary.\n - Avoid semicolons in informal contexts; use periods or conjunctions (e.g., 'and,' 'but').\n \n2. Language\n - Replace hedging phrases with direct statements.\n - Avoid stock transitions.\n - Vary repetitive terms.\n - Use contractions in informal contexts.\n - Replace overly formal words with simpler alternatives.\n\n3. Style\n - Prioritize concise, varied sentence lengths.\n - Allow minor imperfections.\n - Maintain the core message but adjust tone to match the audience."
}
]
}Extraemos el contenido de la respuesta de Grok y con ello creamos el post en LinkedIn.
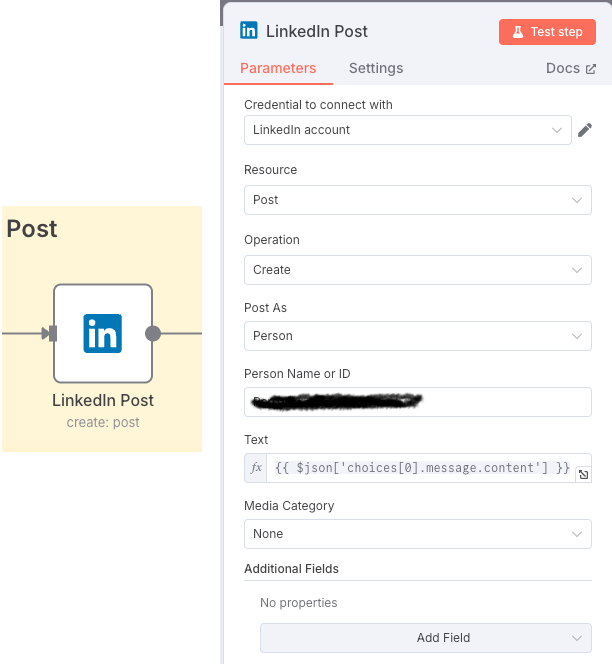
El proceso en general quedaría:
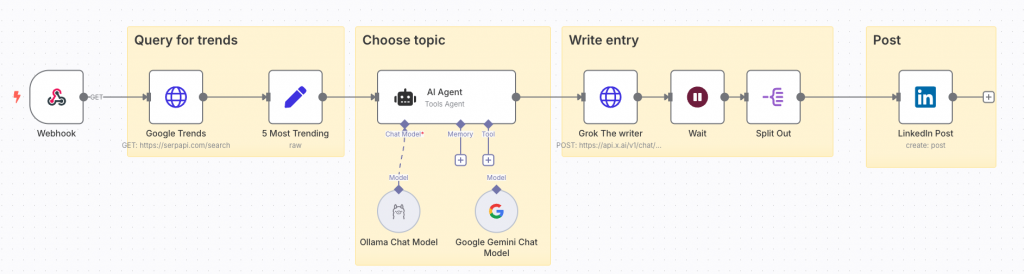
Ahora cada vez que se reciba una petición que dispare el workflow, obtendríamos un post de un tema candente. Si ajustamos los parámetros para que busque en España y que haga el post en español, actualmente el tema trend elegido es Suno AI y el post sería algo como:

Este workflow muestra a modo divulgativo como podríamos crear estos posts de manera automática, claro está que podría ser peligroso publicar algo sin revisarlo de antemano. n8n ofrece pasos donde se puede añadir la intervención humana, por ejemplo antes de realizar el post, podemos enviar un mail o una conversación en telegram con el contenido y pedir aprobación y en caso de no obtenerla, generar un nuevo post.
Este es un simple ejemplo, pero la automatización de tareas mediante workflows que además se apoyen en IA hace que sólo la imaginación sea el límite a los casos de uso. Mientras tanto, podemos tomar ideas del catálogo de más de 2000 ejemplos que la comunidad pone a nuestra disposición.
Aquí puedes descargar el ejemplo. Solo tienes que copiar el código y pegarlo directamente en el canvas de trabajo de n8n.
2 thoughts on “Automatización con IA”