Si bien por la imagen pueda parecer que hablaremos de Dora la exploradora, no es así; aunque podría, ya que últimamente veo muchos capítulos de ella. Vamos a hablar las métricas DORA (DevOps Research and Assessment)
En el propio acrónimo DORA aparece nombrado DevOps, y es que la implementación exitosa de DevOps se ha convertido en un objetivo clave para muchas organizaciones, ya que la dependencia del software desarrollado cada vez es mayor. El enfoque de DevOps busca mejorar la colaboración entre los equipos de desarrollo y operaciones, acelerar la entrega de software y aumentar la calidad y fiabilidad de las aplicaciones. Para medir y mejorar la efectividad de las prácticas de DevOps, las métricas DORA se han establecido como una ayuda muy valiosa.
Las métricas DORA son un conjunto de indicadores clave de rendimiento (KPI, por sus siglas en inglés) desarrollados por el equipo de investigación de Google para evaluar y cuantificar el desempeño de las iniciativas de DevOps. Estas métricas se centran en cuatro áreas principales en su versión original (2020) y posteriormente ampliada con una quinta área:
- Frecuencia de despliegue: frecuencia con la que una organización pasa a producción.
- Tiempo de espera para los cambios: tiempo que tarda un commit en pasar a producción.
- Tiempo medio de recuperación: tiempo que tarda una organización en recuperarse de un fallo en producción.
- Tasa de fracaso de cambios: porcentaje de implantaciones que provocan un fallo en la producción.
- Fiabilidad: capacidad para cumplir o superar sus objetivos de fiabilidad
Las métricas DORA se han convertido en el estándar para medir la eficacia de los equipos de desarrollo de software y pueden proporcionar información crucial sobre las áreas de crecimiento. Estas métricas proporcionan una visión holística del estado de la implementación de DevOps y ayudan a las organizaciones a identificar áreas de mejora y a establecer objetivos claros; podemos decir que son esenciales para las organizaciones que buscan modernizarse y para aquellas que quieren obtener una ventaja frente a sus competidores. Vamos a ver con un poco más de detalle las cuatro primeras métricas que son las más extendidas.
Frecuencia de despliegue
La frecuencia de despliegue (Deployment Frequeny DF) es la frecuencia con la que se despliegan los cambios en producción, es decir, la consistencia con la que se entrega el software al usuario final. Esta métrica es beneficiosa para determinar si un equipo está cumpliendo los objetivos de entrega. Según el equipo de DORA, podemos clasificar el rendimiento según estos puntos de referencia para la en cuanto a la frecuencia de despliegue:
- Rendimiento de élite: Varias veces al día
- Alto rendimiento: De una vez a la semana a una vez al mes
- Rendimiento medio: De una vez al mes a una vez cada seis meses
- Rendimiento bajo: Menos de una vez cada seis meses
La mejor manera de optimizar la DF es realizando despliegues pequeños agrupando varios cambios, en lugar de esperar a tener muchos cambios acumulados. Esto nos ayudará a detectar cuanto antes los fallos y será más fácil encontrarlo puesto que las modificaciones son menores. Además, puede ayudar a revelar cuellos de botella en el proceso de desarrollo o indicar que los proyectos son demasiado complejos.
Tiempo de espera para los cambios
El tiempo de espera para cambios (Lead time for changes, LTC) es el tiempo que transcurre entre la realización de un commit y la puesta producción. El LTC indica el grado de agilidad de una empresa a la hora de llevar el código disponible a producción. De poco vale que los equipos realicen commits con el código actualizado de manera muy rápida si luego los cambios no se transportan a producción. El equipo de DORA identificó estos puntos de referencia para el rendimiento:
- Rendimiento de élite: Menos de una hora
- Alto rendimiento: De un día a una semana
- Rendimiento medio: De un mes a seis meses
- Rendimiento bajo: Más de seis meses
LTC puede ayudarnos a revelar ineficiencias en el proceso si los equipos tardan semanas o meses en poder ver su código en producción. Las causas pueden ser muchas, como tiempos de realización de pruebas o ventanas temporales específicas para realizar despliegues conjuntos. En este sentido el uso de técnicas de integración continua y entrega continua (CI/CD) ayudan a minimizar el LTC. Animar al equipo de operaciones y desarrolladores a colaborar estrechamente o incluso poner objetivos conjuntos son palancas que ayudan a que todos colaboren y tengan un conocimiento exhaustivo del software, minimizando el LTC. En este mismo campo, la creación de pruebas y escaneos automatizados e integrados en los pipelines de CI/CD, ahorrarán mucho más tiempo y mejorarán el proceso en general.
Dado que hay varias fases entre el inicio y el despliegue de un cambio, conviene definir cada paso del proceso y hacer un seguimiento de cuánto tiempo lleva cada uno. De esta manera, podremos detectar fácilmente los cuellos de botella o anomalías en un caso particular. Examinando la duración del ciclo podemos obtener una imagen completa de cómo funciona el equipo y más información sobre dónde se puede optimizar para ahorrar tiempo.
Como todo en esta vida, debemos vigilar un equilibrio a la hora de mejorar el LTC. Si mejoramos el LTC pero hacemos que el equipo se tensione para poder mantener el ritmo, podemos tener personas que estén bajo mucha presión y acaben abandonando la organización o introducir fallos de calidad sacrificando la experiencia de usuario. Efectos claramente indeseados.
Aunque tengamos la tentación de comparar el rendimiento de un equipo con otro, hay que tener en cuenta que la dificultad de las tareas asignadas o el dominio en el que trabajan pueden no ser equiparables. En lugar de comparar el LTC del equipo con el de otros equipos u organizaciones, es mejor evaluar esta métrica a lo largo del tiempo y considerarla un indicador que mida el crecimiento o estancamiento de ese equipo.
Tiempo medio de recuperación
El tiempo medio de recuperación (Mean Time To Recover, MTTR) es la cantidad media de tiempo que tarda el equipo en restablecer el servicio cuando se produce una interrupción en producción, como podría ser un apagón. Esta métrica ofrece una visión del tiempo que tarda en recuperarse un sistema.
- Rendimiento de élite: Menos de una hora
- Alto rendimiento: Menos de un dia
- Rendimiento medio: De un día a una semana
- Rendimiento bajo: Más de una semana
Para minimizar el impacto de un servicio degradado en el flujo de valor, debe haber el menor tiempo de inactividad posible. Dependiendo de la criticidad de los servicios desplegados y el tiempo que se tarda en restablecer los servicios, se debe considerar la posibilidad de utilizar indicadores a modo de alarma para poder desactivar rápidamente un cambio que provoque degradación, sin causar demasiadas interrupciones. Cuantificar las perdidas a nivel económico por cada hora de servicio parado puede ayudar a determinar la criticidad del servicio. Como hemos visto, si los despliegues se realizan en envíos de lotes pequeños, será más fácil descubrir y resolver los problemas, mejorando el MTTR.
Otra métrica que podemos tener dentro de este campo es el tiempo medio hasta la detección del fallo (Mean Time To Discover MTTD) que es diferente del tiempo medio hasta la recuperación. El tiempo que tarde su equipo en detectar un problema influirá en su MTTR: cuanto más rápido detecte su equipo un problema, más rápido podrá restablecerse el servicio.
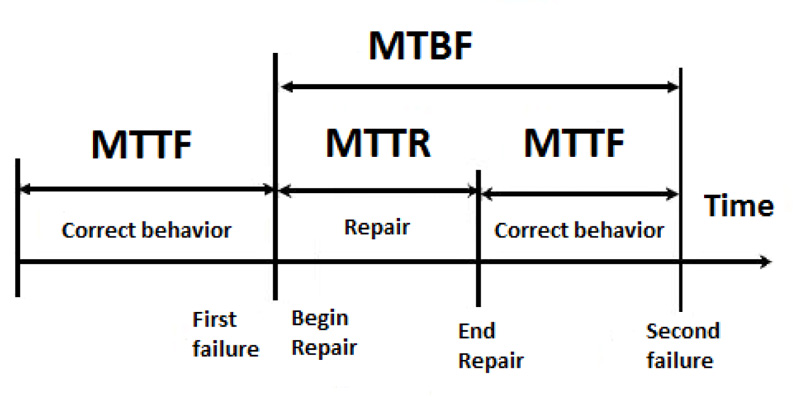
Cambios drásticos para mejorar el MTTR, por ejemplo disminuyendo el número de pruebas antes de desplegar, pueden introducir mermas en la calidad, que podremos controlar con el siguiente indicador. Por esto es mejor introducir pequeños cambios en el proceso que aseguren que son duraderos y completos y hacer seguimiento del MTTR a lo largo del tiempo para ver cómo evoluciona el conjunto.
Tasa de fracaso de cambios
La tasa de fracaso de cambios (Change Failure Rate CFR) es el porcentaje de versiones que producen tiempo de inactividad, degradación del servicio o reversión de lo desplegado. Este indicador muestra la eficacia de un equipo a la hora de implementar cambios.
- Rendimiento de élite: 0%-15%
- Alto rendimiento: 16%-30%
- Rendimiento medio: 16%-30%
- Rendimiento bajo: 16%-30%
Esta métrica es muy valiosa porque pone de manifiesto que no por hacer muchos despliegues se aporta más valor. Los despliegues tienen que encontrarse libres de fallos y no degradar el servicio. Esta medida es porcentual, esto evita que equipos que realizan pocos despliegues, al tener pocos fallos puedan pensar que tienen más éxito implementando. Dicho de otra manera, si nos encontramos en un entorno donde se siguen prácticas de CI/CD puede que se vea un mayor número de fallos debido a la multitud de despliegues, pero si el CFR es bajo, estos equipos tendrán alta su tasa de éxito general y una velocidad de despliegue exitoso mayor.
Otro dato que podemos sacar de este indicador es cuanto tiempo se dedica a solucionar problemas en lugar de desarrollar nuevos proyectos, lo que incide directamente en el flujo de valor. Nuevamente, lo mejor en este indicador es que no se compare entre equipos u organizaciones y que se realice seguimiento dentro del propio equipo, estableciendo objetivos particulares en cada caso y viendo su evolución.
Visión conjunta
Estas cuatro métricas por separado pueden darnos datos de la manera en la que se opera, pero cuando se obtiene la mayor información es cuando se combinan y se consideran de manera conjunta en un mismo contexto. El tiempo de espera para los cambios y la frecuencia de despliegue proporcionan información sobre la velocidad de un equipo y la rapidez con la que responden a las necesidades (siempre cambiantes) de los usuarios. Por otro lado, el tiempo medio de recuperación y la tasa de fallos en los cambios indican la estabilidad de un servicio y la capacidad de reacción del equipo ante las interrupciones o fallos.
Comparando las cuatro métricas clave, se puede evaluar hasta qué punto la organización equilibra velocidad y estabilidad. Si el tiempo de espera para los cambios está dentro de una semana, pero la tasa de fallos en los cambios es alta, entonces los equipos pueden estar forzando el despliegue de los cambios antes de que estén listos, o puede que no se esté dedicando el tiempo necesario para realizar pruebas. Si, por el contrario, despliegan una vez al mes y su tiempo medio de recuperación y la tasa de fracaso de cambios son elevados, es posible que el equipo esté dedicando más tiempo a corregir código que a mejorar el producto.
Dado que las métricas DORA proporcionan una visión de alto nivel del rendimiento de los equipos, son muy beneficiosas para las organizaciones que intentan modernizarse y obtener mejores resultados. Las métricas DORA pueden ayudar a identificar exactamente dónde y cómo mejorar la producción del software. Con el tiempo, los equipos pueden medir dónde han crecido y qué casos se han estancado, pudiendo centrar los esfuerzos en ciertas áreas de mejora.
No obstante las métricas DORA son sólo una herramienta. Para sacarles el máximo partido, los responsables deben conocer la organización y los equipos y aprovechar ese conocimiento para orientar sus objetivos y determinar cómo invertir y focalizar eficazmente sus recursos.
Lo que veo que le falta a estas métricas es una relación real con el negocio, que es lo que importa.