Hasta no hace tanto, la manera más normal de abordar la construcción de una solución software, era de manera monolítica, todos los elementos necesarios, se compilaban dentro de la misma aplicación. Esto supone que las dependencias entre las distintas partes de la solución, están estrechamente relacionadas, de manera que cuando se toca una parte de la aplicación, toda ella puede resultar afectada y que cuanto más grande es la aplicación y más funcionalidades se le añaden, más difícil es mantenerla con un rendimiento óptimo y libre de problemas, lo que implica que el ciclo de releases se alarga.
Mediante el uso de patrones como MVC (modelo vista controlador) se consigue desacoplar de cierta manera los datos, la interfaz y la lógica de control, pudiendo realizarlas de modo separado; este desacoplamiento entre las capas ofrece la libertad de poder modificar por ejemplo la interfaz sin necesidad de tocar código de lógica de negocio, lo cual reduce sustancialmente las pruebas a realizar en cada cambio.
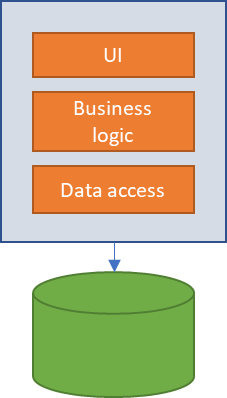
Pero esto no es suficiente, cuando dentro de una empresa se van generando nuevas aplicaciones, ciertas funcionalidades se van repitiendo entre ellas, por ejemplo, consultar información de un cliente, obtener stock de un material, los ejemplos son innumerables.Supongamos que la función de obtener cliente la tenemos disponible en tres aplicaciones, en un diseño monolítico, cada aplicación tendría su propio código de acceso al cliente, e incluso podría darse que tuviera su propia base de datos, perdiendo así la consistencia del dato en la empresa. Si hubiera que modificar el acceso a la información del cliente (por ejemplo, por cambio de base de datos), deberíamos rehacer las tres aplicaciones y volverlas a probar, con el consiguiente coste en tiempo y recursos, es decir dinero.
Gracias a la arquitectura orientada a servicios (SOA), gran parte de estos problemas quedaron solucionados. Rompiendo la aplicación en distintos servicios y haciéndolos disponibles a través de un bus de servicios empresariales (ESB), las aplicaciones que quisieran consultar información de un cliente solo tendrían que conectarse al ESB y usar el servicio correspondiente. Esta arquitectura tiene un talón de Aquiles: el ESB. En caso de que no funcione el ESB, todas las aplicaciones que dependan de él quedarán inutilizadas.
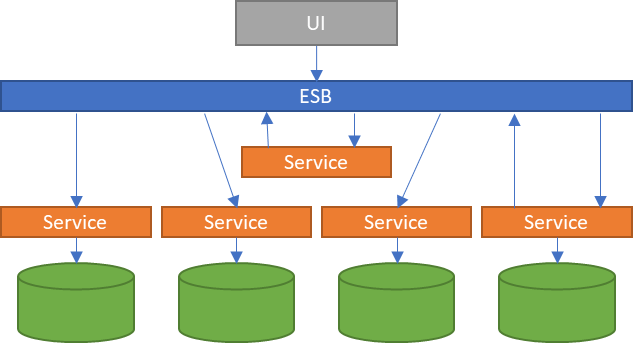
La arquitectura de microservicios va un paso más allá, una evolución de SOA permitiendo la comunicación directa entre servicios, eliminando así el problema de depender de un ESB que orqueste las llamadas entre ellos.
La arquitectura de microservicios nos va a permitir desarrollar las aplicaciones como un conjunto de pequeños servicios que se ejecutan de manera aislada, en su propio proceso (incluso máquina) y que se comunican entre ellos (no hay ESB) mediante protocolos ligeros, a todo esto, ha ayudado la tecnología de contenedores pudiendo romper las aplicaciones en pequeños servicios autosuficientes y autocontenidos, pudiendo incluir sus propias bases de datos, hablaremos de ellos en otro artículo.
Seguramente el lector ya va viendo que esta arquitectura tiene muchas ventajas, pero también tiene inconvenientes que veremos más adelante.
Un tema que hay que tener en cuenta, es que al trabajar con microservicios no se cambia solo la manera de pensar la arquitectura de la solución a nivel de código, sino que existe una restructuración de los equipos para desarrollar estas partes de la aplicación de manera separada pero que deben estar preparados para comunicarse entre ellos y para responder ante fallos al llamar a otros servicios.
Una de las grandes ventajas es que podemos crear equipos separados para realizar cada uno de estos microservicios, usando tecnologías diferentes para cada microservicio y simplemente publicando la API (Application Programming Interface) y hacer que se llamen entre ellos siguiendo un protocolo pactado. Dividiendo la aplicación en microservicios, podremos crear grupos de trabajo separados, facilitando la implementación de metodologías agile para el desarrollo, donde podemos tener por ejemplo un squad totalmente focalizado en reporting de tesorería que realiza el microservicio en Java y otro squad focalizado en realizar un microservicio de forecast de cobros realizando el trabajo en R. Esto no impide que puedan llamarse entre ambos servicios y además permite que cada uno de los equipos trabaje a su ritmo, simplemente tienen que asegurar que su parte funciona, y así poder compartir un proceso entre varias aplicaciones, sin tener un acoplamiento directo.
Los microservicios son funcionalidades autocontenidas, es decir pueden funcionar por separado realizando aquella acción para los que fueron diseñados, pudiendo hacerse despliegues individuales de cada uno de ellos, favoreciendo los procesos de CI/CD. Del mismo modo que funcionan por separado, también fallan por separado, lo cual es una gran noticia también, ya que si un microservicio cae, solo deja de funcionar esa parte de la aplicación, pero el resto de la aplicación puede seguir funcionando sin problema.
A pesar de sus ventajas para la escalabilidad y resiliencia de la solución, los microservicios también presentan desventajas que habrá que tener en cuenta durante el desarrollo, como la complejidad de los test de integración, mayores retos de seguridad, creciente tráfico de red por las llamadas remotas, etc.
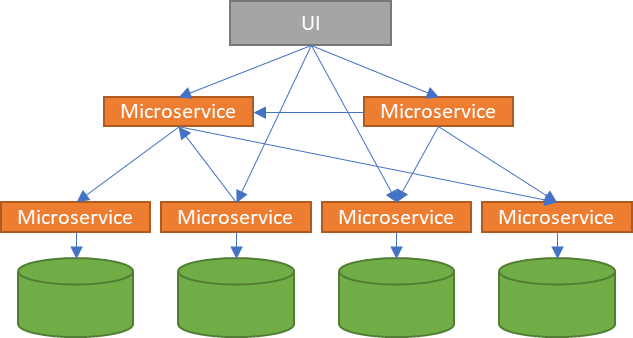
Cuando una arquitectura de microservicios crece, dado que pueden llamarse entre los diferentes microservicios de manera libre, nos encontraremos ante una situación en la que estarán atados entre ellos de manera que será muy difícil conocer que microservicio es llamado por qué microservicio y las implicaciones que puede tener en otros procesos cuando realizamos algún cambio en uno de los microservicios.
Hemos avanzado desde una aplicación monolítica donde cada cambio implicaba compilar, probar y desplegar toda la aplicación a un montón de microservicios, capaces de comunicarse entre ellos para facilitar la escalabilidad y la resiliencia, pero a medida que el landscape de microservicios va creciendo, también crece la dificultad para comprender el flujo de trabajo y resulta complejo de mantener la solución.
Para ayudar a facilitar la gestión del landscape de microservicios, podemos apoyarnos en las arquitecturas impulsadas por evento, ya que se adaptan muy bien a los microservicios y permitirán superar algunos de los inconvenientes que hemos visto anteriormente.
En una arquitectura basada en eventos, cuando un sistema realiza un cambio en su dominio, informa al mundo exterior a través de un evento. El emisor simplemente se encarga de anunciar ese cambio, pero no le importa si hay otro sistema escuchando o lo que haga con el aviso que ha emitido, por ejemplo, cuando estamos comprando en una web y pulsamos sobre “añadir al carrito”, el sistema anunciaría que “se ha añadido el objeto al carrito”, que puede tener otros sistemas escuchando (o no) y actuar sobre ese evento, por ejemplo el evento puede servir para saber que otro sistema tiene que bloquear stock, o que tiene que enseñarle otros artículos relacionados con el objeto que acaba de añadir al carrito, etc. De esta manera, es muy fácil añadir nuevos servicios al ecosistema, simplemente tienen que lanzar al aire eventos de las acciones que han ocurrido y son el resto de servicios los que se encargarán de “escuchar” y actuar en relación a esta llamada o bien escuchar los eventos que lanzan otros, actuando como consumidor y reaccionar sobre ellos.
Desde el punto de vista de negocio, cuando se expresa un proceso a cubrir por la aplicación, se habla de acciones que van ligadas y con interdependencias entre ellas; ver como se ha cubierto el proceso mediante eventos y el orden en el que se ejecutan, es mucho más sencillo que una caja negra de una aplicación monolítica; es mucho más sencillo poder ver que después del evento A se debe ejecutar el evento B, que no pulsar un botón y obtener un resultado que no se sabe cómo se ha obtenido porque está ofuscado en la lógica interna de la aplicación.
A la hora de emitir eventos, se puede realizar utilizando diferentes patrones, algunos de ellos son:
- Event Notification: En este patrón, simplemente indicamos lo que ha pasado, sin dar mucha más información, es el patrón más sencillo de implementar a nivel de evento, pero tiene otros inconvenientes, por ejemplo, podríamos emitir un evento de “Se ha realizado la compra”, y los consumidores del evento, se tienen que encargar de preguntar qué ha comprado, o si se ha aplicado descuento, o lo que aplique a cada consumidor, pudiendo generar una cascada de llamadas por parte de cada consumidor para obtener los datos que necesiten.
- Event-Carried State Transfer: En este patron, ademas de enviar el evento, se envía un estado de dicho evento, en el ejemplo anterior, además de avisar de que se ha realizado la compra, el mensaje podría llevar datos sobre los elementos comprados, descuentos aplicados, dirección de facturación, etc. Está información puede ser utilizada por los consumidores del evento, sin necesidad de tener que realizar llamadas adicionales.
- Event Sourcing: La idea de este patrón es que cualquier cambio que se realice en un sistema, se registre como evento y quede grabado en un log, de manera que podamos reconstruir el estado del sistema a partir del histórico de eventos producidos en él, convirtiéndose el almacén de eventos en el single point of truth
Para la gestión de los mensajes y su envío entre sistemas y microservicios, existen múltiples soluciones como Rabbit MQ , Aws Kinesis y otros, aunque la solución más conocida probablemente sea Apache Kafka.
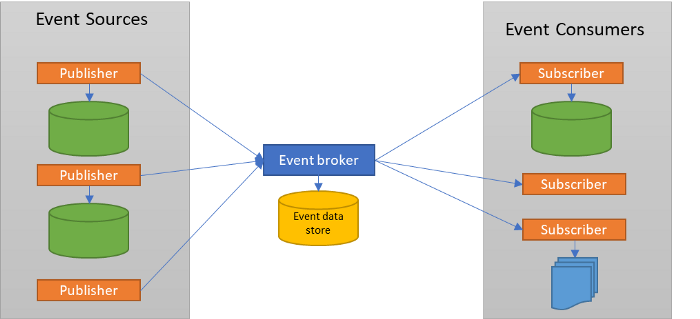
Sin querer entrar en mucho detalle en este artículo (ya lo haremos en otro), hablaremos de Kafka, gracias al cual, por ejemplo podremos gestionar las colas de eventos, crear particiones para balancear cargas entre distintos emisores y receptores, mantener un registro de todos los eventos y sus estados, usar conectores para distintos sistemas, etc, y todo ello manejando grandes volúmenes de flujos de información de manera distribuida. ¿Esto que significa a nivel de escalabilidad y resiliencia? Significa mucho.
Ya hemos visto que mediante Kafka, introducir nuevos generadores, procesadores o consumidores de eventos es algo sencillo (emitir y consumir eventos) y lo podríamos hacer con zero downtime, balanceando la carga entre los disponibles, pero además, Kafka puede mantener una base de datos única con todo el histórico de los eventos sucedidos en los sistemas y los datos asociados a ellos, con lo que en caso de que un nodo con sus correspondientes microservicios y bases de datos dejara de funcionar, podríamos levantar un nuevo nodo y que se nutriera de los eventos necesarios almacenados en Kafka, llegando al estado de datos del nodo anterior en muy poco tiempo y de manera automática. Con la llegada de los servicios en la nube, cada vez más se siente una necesidad de realizar microservicios de manera que tengamos aplicaciones muy flexibles y poco acopladas, pero para conseguir un buen resultado en la aplicación, es necesario unir estos microservicios de una manera que sea mantenible y traceable a la vez que segura y resiliente. La arquitectura basada en eventos dispone de muchas características que la hacen una muy buena opción para unir servicios. Aunque existen muchas plataformas para la gestión de eventos, Apache Kafka es una de las más conocidas, con gran capacidad de escalado y rendimiento, ofreciendo entre otros, servicios de colas por subscripción, transformación de datos, replicación o logs distribuidos.
Interesante repaso sobre el viaje de las arquitecturas.
Gracias