Más o menos todos hemos oido hablar de los LLM (Large Language Models) y de cómo son capaces de mantener conversaciones y ofrecer información muy variada y ser realmente creativos. Por ejemplo, a ChatGPT le podemos pedir una receta de merengue, que nos escriba una poesía sobre un gato en el espacio o que nos explique el funcionamiento de un motor a reacción para un estudiante de primaria. Esto es increiblemente poderoso, pero no todo son ventajas. Lo cierto es que estos modelos, llevan asociados unos costes altos y en bastantes casos, una lentitud en la respuesta que puede llegar a molestar al usuario. Esto se debe en gran parte a la cantidad de parámetros que se evalúan en cada petición, que tiene un coste computacional en tiempo y en dinero.
Pero, si sólo queremos que nos responda sobre la normativa de la empresa, ¿Necesitamos que el modelo sepa como atender nuestras dudas sobre la post combustión de los motores de reacción? Con la aparición de los agentes IA, podemos dividir las tareas y utilizar modelos que sean especializados en esa única tarea. Hace un par de meses, en Nvidia se publicó un paper muy interesante sobre los SLMs (Small Language Models) y de cómo podrían ser la solución para el futuro.
¿Qué es un Small Language Model?
Empezaremos hablando de los LLM, que para simplificar, podemos decir que son unos cerebritos que aprenden de montones de libros, sitios web y conversaciones para responder preguntas, escribir historias o hasta programar. Podemos pensar en ellos como un empleado que ha leído todo internet y puede hablar de cualquier cosa porque lo retiene todo. ¿Y qué le hace tan capaz? Los parámetros.
Los parámetros son como las «conexiones neuronales» que forman el núcleo de un LLM. Técnicamente, son números, valores matemáticos que el modelo ajusta durante su entrenamiento para «recordar» y «entender» información. Podemos pensar en los LLM como un mapa mental gigante. Cada parámetro es una intersección en ese mapa que conecta ideas, palabras o conceptos. Un LLM con más parámetros tiene un mapa más detallado y complejo. De manera general, podemos decir que tener más parámetros permiten al LLM manejar tareas más complejas, como razonar lógicamente, traducir idiomas o generar código. Es decir, los parámetros sirven para que el modelo sea «más inteligente» y menos propenso a errores. (Nota: no debemos basarnos en el número de parámetros para decir si un modelo es mejor que otro o no. Normalmente modelos con menos parámetros superan en rendimiento a modelos con más parametros de generaciones anteriores, por ejemplo Llama 3 con 8B de parámetros obtiene una puntuación de 68.4 en MMLU mientras que Llama 2 con 13B de parámetros sólo obtiene una puntuación de 54.8)
Pero no todo son ventajas. Más parámetros supone que cuesta más entrenar, depurar y ejecutar, en otras palabras, mayor gasto energético y computacional; más coste. Para que podamos hacernos una idea, GPT-3 tiene 175 billones de parámetros, Llama 2 tiene (en una de sus versiones) 176 billones y GPT-4 se rumorea que tiene sobre 1.76 trillones de parámetros (billones y trillones americanos). Eso son muchos parámetros para entrenar y consultar.
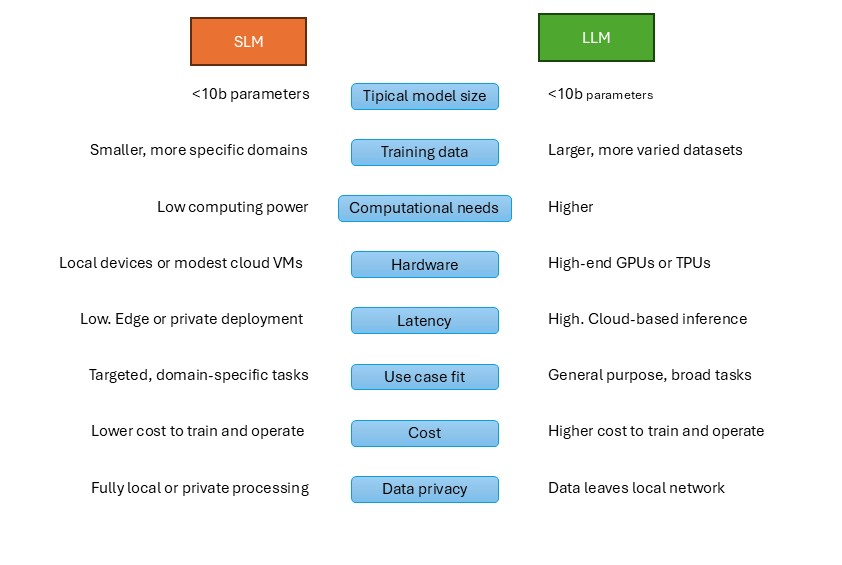
Los SLMs son igualmente modelos de lenguaje natural pero que tienen un tamaño reducido, típicamente entre 100 millones y unos pocos billones de parámetros. De manera genérica, podemos tomar los SLMs como modelos que caben en dispositivos de consumo común (menos de 10B parámetros en 2025) y pueden inferir con baja latencia, suficiente para un usuario.
Los SLMs surgieron como respuesta a los desafíos ya nombrados de los Large Language Models (LLMs), como son el alto consumo de energía, y costes de entrenamiento y ejecución. Utilizando técnicas como destilación de conocimiento (donde un modelo grande «enseña» de manera resumida a uno pequeño) y cuantización (técnica de optimización que reduce la precisión numérica de los datos del modelo de IA), se obtienen modelos donde se «mantiene» el rendimiento mientras reducen el tamaño. «Mantiene» está entre comillas, porque realmente el modelo se degrada en uno u otro sentido, pero dependiendo de los propósitos para lo<s que los necesitemos, son más que válidos.
SLMs nos van a permitir ejecutar modelos en dispositivos locales sin depender de la nube, lo que los hace especialmente interesantes a la hora de reducir costes y mantener la privacidad.
Podemos encontrar múltiples SLMs disponibles, por ejemplo:
- Microsoft Phi-3: Con 3.8 billones de parámetros, es uno de los más eficientes. Entrenado en datos sintéticos de alta calidad, destaca en razonamiento y código. Puede ejecutarse incluso en un smartphone con solo 4GB de RAM. (link)
- Google Gemma: Basado en Gemini, tiene versiones de 2B y 7B parámetros. Es ligero y versátil para tareas como traducción y resumen de texto. (link)
- Meta Llama 3 (versión pequeña): Con 1B parámetros, es una evolución de Llama 2. Soporta multilenguaje y es ideal para chatbots. (link)
Pero no son los únicos, hay muchos más que podemos probar fácilmente en nuestros ordenadores mediante software como Ollama, LMStudio o Jan AI entre otros muchos.
SLMs vs. LLMs
Las diferencias entre SLMs y LLMs son varias, pero podemos resumirlas en:
- Tamaño y Recursos: SLMs usan 10-100 veces menos parámetros, reduciendo el entrenamiento de semanas a días. Si un LLM consume energía equivalente a un hogar por hora de uso; un SLM, sería como una bombilla LED.
- Rendimiento: En benchmarks como GLUE o MMLU, SLMs como Phi-3 logran 70-80% del score de LLMs en tareas simples (clasificación de texto o Q&A básicas), pero fallan en razonamiento complejo. También hay que decir que con fine-tunning, cierran bastante esta brecha.
- Velocidad y Coste: SLMs infieren respuestas en milisegundos en hardware modesto (usando CPUs, no caras GPUs).
- Privacidad: En el caso de los SLMs, los datos no salen del dispositivo, mientras que con los LLM dependemos de la capacidad de computación de la nube, tendiendo que mover ahí los datos.
- Contextos: Los SLM manejan contextos más reducidos y menos generalizados, mientras que los LLMs manejan contextos mucho más grandes. Un SLM puede tener contextos de unos 8k-32k tokens, mientras un LLM como GPT4 puede tener contextos desde 128k hasta más de un millón de tokens.
Podríamos decir que los SLMs son «IA ligera» para el mundo real, mientras LLMs son para investigación avanzada, tal y como comenta el paper de Nvidia.
¿Es el futuro de los SLM?
Según informes de Gartner, para 2025, el 75% de los datos empresariales se procesarán en el edge, impulsando esta tecnología.
Queda claro que los LLMs son más grandes y dependen de infraestructuras en la nube mucho más complejas de mantener y evolucionar (con todo lo que ello comporta), pero la clave es si los SLMs son capaces y versátiles para dar valor real, tal y como lo dan los LLM. A este respecto, los autores argumentan en el paper que los SLMs son:
- Suficientemente potentes para aplicaciones que usen agentes: Con avances en entrenamiento, SLMs como Microsoft Phi-3 (7B) o NVIDIA Nemotron-H (4.8B) igualan o superan LLMs de generaciones previas en razonamiento, generación de código y llamadas a herramientas, con hasta 15x más velocidad. Por ejemplo, DeepSeek-R1-Distill (7B) supera a Claude-3.5 en razonamiento.
- Más adecuados operativamente: Los agentes IA trabajan con tareas complejas descompuestas en subtareas simples, donde los SLMs brillan por su flexibilidad y capacidad de adaptación a sistemas heterogéneos (mezclando SLMs y LLMs).
- Más económicos: Inferencia 10-30x más barata en latencia, energía y FLOPs. Además, es posible realizar fine-tunning de manera más rápida (horas vs. semanas) y despliegue en edge (dispositivos locales), lo que reduce los costes y mejora la privacidad.
En 2025, encuestas como la de Cloudera indican que el 96% de empresas están abordando los agentes IA, con un mercado de 5.2B$ creciendo a 200B$ para 2034. Aquí, SLMs ofrecen ventajas concretas:
- Eficiencia económica: Debido a la eficiencia económica de los SLMs, para empresas con volúmenes altos de consultas (por ejemplo, chatbots en e-commerce), el uso de SLMs puede llegar a reducir el OPEX un 50-90% (según análisis de McKinsey sobre IA generativa). Poder desplegar en edge evita dependencia de infraestructuras caras en la nube.
- Flexibilidad y adaptación: SLMs se pueden adatar rápidamente mediante fine-tunning para realizar tareas específicas, como análisis de datos en IoT u optimización de rutas en logística. Con los SLMs, más empresas pueden crear modelos personalizados, fomentando innovación sin barreras de escala.
- Sostenibilidad y cumplimiento: Menor huella energética y alineamiento con regulaciones como GDPR (mantener los datos locales).
Pero no todo es ideal para los SLMs. Los LLMs tienen mejor comprensión semántica general, y dependiendo del uso que se les dé, se podrían producir economías de escala en la nube donde harían que su inferencia fuera más barata a largo plazo.
Por otro lado, ya hemos visto que los SLMs actúan bien cuando son tareas concretas, esto quiere decir que podrían fallar en tareas no descompuestas, que un LLM sí podría atender de manera correcta, en otra palabras, los SLM son más propensos al fallo cuando hay variaciones. En una conversación abierta en la que se pueda hablar de cualquier tema, es muy probable que un LLM de mejores resultados.
En mi opinion, los SLMs son el futuro… con matices. Creo que los SLMs serán el futuro para la mayoría de empresas que usen agentes IA; la evidencia empírica la tenemos en que los SLMs ya rivalizan en rendimiento mientras bajan los costes drásticamente en muchas tareas. Por otro lado, democratizan la IA, haciendo posible que las PYMES puedan trabajar con sus propios modelos y ajustarlos a sus necesidades sin depender de grandes empresas como Microsoft o Google.
Pero luego están los matices, no es «todo o nada». Creo que el futuro serán sistemas híbridos: SLMs para el 80% de tareas repetitivas (por ejemplo, procesamiento de datos en supply chain), LLMs para el 20% creativo. Mediante sistemas híbridos, podemos usar SLMs para rutinas diarias y LLMs solo para tareas complejas, optimizando recursos.
Momento de probar SLMs: ahorro y una IA más ecológica.